Google型始终在计算机视觉任务中获得最先进的结果,包括对象检测和视频分类。与逐像素处理图像的标准卷积方法相比,视觉变换器(ViT) 将图像视为一系列补丁标记(即,由多个像素组成的图像的较小部分或“补丁” )。这意味着在每一层,ViT 模型使用多头自注意力,根据每对令牌之间的关系重新组合和处理补丁令牌。这样做时,ViT 模型有能力构建整个图像的全局表示。
在输入级别,通过将图像均匀地分割成多个片段来形成标记,例如,将 512 x 512 像素的图像分割成 16 x 16 像素地块。在中间层,上一层的输出成为下一层的标记。在视频的情况下,视频“小管”,例如 16x16x2 视频片段(2 帧上的 16×16 图像)成为标记。视觉标记的质量和数量决定了 Vision Transformer 的整体质量。
许多 Vision Transformer 架构的主要挑战是它们通常需要太多的令牌才能获得合理的结果。例如,即使使用 16×16 补丁标记化,单个 512×512 图像也对应于 1024 个标记。对于具有多帧的视频,这会导致每一层都需要处理数以万计的令牌。考虑到 Transformer 的计算量随标记数量呈二次方增加,这通常会使 Transformer 难以处理更大的图像和更长的视频。这就引出了一个问题:真的有必要在每一层处理那么多令牌吗?
在“ TokenLearner:8个学习的令牌可以为图像和视频做什么?”,其早期版本已在NeurIPS 2021 上展示,我们自适应地展示了生成较少数量的令牌,而不是总是依赖于通过统一分裂形成的令牌,使 Vision Transformers 运行得更快,性能也更好。TokenLearner 是一个可学习的模块,它采用类似图像的张量(即输入)并生成一个小组标记。该模块可以放置在感兴趣的模型内的各个不同位置,从而显着减少在所有后续层中要处理的令牌数量。实验表明,使用 TokenLearner 可以在不损害分类性能的情况下节省一半或更多的内存和计算量,并且由于其适应输入的能力,它甚至提高了准确性。
Token Learner
我们使用简单的空间注意力方法来实现 TokenLearner。为了生成每个学习的标记,我们计算了一个空间注意力图,突出显示重要区域(使用卷积层或MLP)。然后将这种空间注意力图应用于输入以对每个区域进行不同的加权(并丢弃不必要的区域),并将结果空间池化以生成最终的学习标记。这并行重复多次,从原始输入中产生几个(~10)个标记。这也可以看作是根据权重值执行像素的软选择,然后是全局平均池化。请注意,计算注意力图的函数由不同的可学习参数集控制,并以端到端的方式进行训练。这允许优化注意力函数以捕获输入中的不同空间信息。下图说明了该过程。

TokenLearner 模块学习为每个输出标记生成空间注意力图,并使用它来抽象输入以进行标记化。在实践中,学习了多个空间注意力函数,应用于输入,并并行生成不同的标记向量。
因此,TokenLearner 不是处理固定的、统一标记化的输入,而是使模型能够处理与特定识别任务相关的较少数量的标记。也就是说,(1)我们启用了自适应标记化,以便可以根据输入动态选择标记,并且(2)这有效地减少了标记的总数,大大减少了网络执行的计算。这些动态且自适应地生成的令牌可以在标准变压器架构,诸如被用于VIT图像和VIVIT视频。
TokenLearner 的放置位置
构建 TokenLearner 模块后,我们必须确定放置它的位置。我们首先尝试使用 224×224 图像将其放置在标准 ViT 架构内的不同位置。TokenLearner 生成的令牌数量为 8 和 16,远低于标准 ViT 使用的 196 或 576 个令牌。下图为ImageNet几次分类精确度和FLOPS在VIT B / 16,这是基本模型用12注意力层上16×16的补丁令牌操作中的各种相对位置插入有TokenLearner的模型。
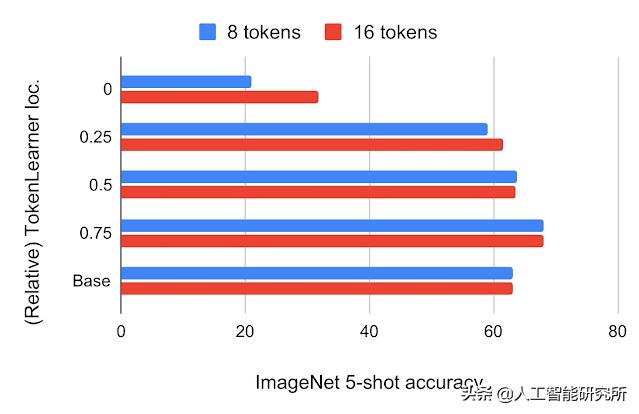
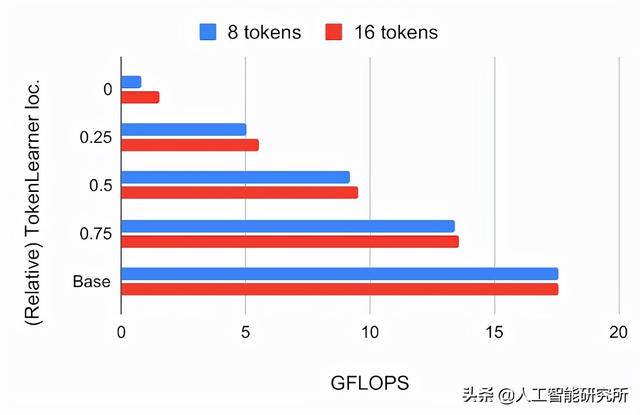
上图:使用JFT 300M预训练的ImageNet 5-shot 传输精度,相对于 ViT B/16 中的相关 TokenLearner 位置。位置 0 表示 TokenLearner 放置在任何 Transformer 层之前。基础是原始的 ViT B/16。底部:计算,以数十亿次浮点运算 (GFLOPS) 来衡量,每个相对 TokenLearner 位置。
我们发现在网络的初始时间四分之一(1/4)之后插入 TokenLearner 可以获得与基线几乎相同的准确度,同时将计算量减少到基线的三分之一以下。此外,与不使用 TokenLearner 相比,将 TokenLearner 放置在后一层(网络的 3/4 之后)可以获得更好的性能,同时由于其自适应性,性能更快。由于TokenLearner前后的token数量相差很大(例如196个之前和8个之后),TokenLearner模块之后的transformers的相对计算变得几乎可以忽略不计。
与 ViT 的比较
我们将带有 TokenLearner 的标准 ViT 模型与没有它的模型进行了比较,同时在 ImageNet 小样本传输上遵循相同的设置。TokenLearner 被放置在每个 ViT 模型中间的不同位置,例如 1/2 和 3/4。下图显示了有和没有 TokenLearner 的模型的性能/计算权衡。

使用和不使用 TokenLearner 的各种版本 ViT 模型在 ImageNet 分类上的性能。这些模型使用 JFT 300M 进行了预训练。模型越靠近每个图的左上角越好,这意味着它运行得更快并且性能更好。观察 TokenLearner 模型在准确性和计算方面的表现如何优于 ViT。
我们还在更大的 ViT 模型中插入了 TokenLearner,并将它们与巨大的ViT G/14 模型进行了比较。在这里,我们将 TokenLearner 应用于 ViT L/10 和 L/8,它们是具有 24 个注意力层的 ViT 模型,以 10×10(或 8×8)块作为初始标记。下图显示,尽管使用更少的参数和更少的计算,TokenLearner 的性能与具有 48 层的巨型 G/14 模型相当。

左:大规模 TokenLearner 模型的分类准确率与 ImageNet 数据集上的 ViT G/14 相比。右:参数数量和 FLOPS 的比较。
高性能视频模型
视频理解是计算机视觉中的关键挑战之一,因此我们在多个视频分类数据集上评估了 TokenLearner。这是通过将 TokenLearner 添加到Video Vision Transformers (ViViT) 中来完成的,它可以被认为是 ViT 的时空版本。TokenLearner 每个时间步学习 8(或 16)个令牌。
当与 ViViT 结合时,TokenLearner 在包括 Kinetics-400、Kinetics-600、Charades 和 AViD 在内的多个流行视频基准测试中获得了最先进的 (SOTA) 性能,在 Kinetics-400 和 Kinetics- 上的性能优于之前的 Transformer 模型600 以及之前在 Charades 和 AViD 上的 CNN 模型。

使用 TokenLearner 的模型在流行的视频基准测试(2021 年 11 月捕获)上的表现优于最先进的模型。左:流行的视频分类任务。右:与 ViViT 模型的比较。
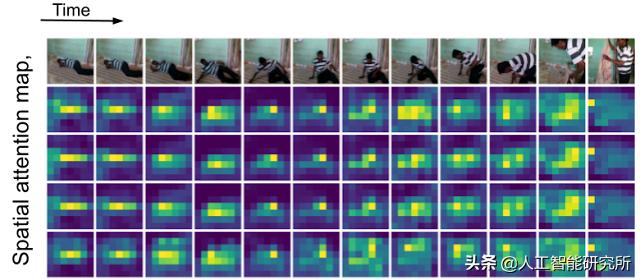
随着时间的推移,TokenLearner 中空间注意力图的可视化。当人在场景中移动时,TokenLearner 会关注不同的空间位置进行标记。
虽然 Vision Transformers 是计算机视觉的强大模型,但大量令牌及其相关的计算量一直是将其应用于更大图像和更长视频的瓶颈。在这个项目中,我们说明保留如此大量的令牌并在整个层集上完全处理它们是没有必要的。此外,我们证明了通过学习一个基于输入图像自适应地提取标记的模块,可以在节省计算量的同时获得更好的性能。提议的 TokenLearner 在视频表示学习任务中特别有效,我们用多个公共数据集证实了这一点。我们工作的预印本和代码是公开的。