文章有点长,我主要是想在一篇文章中把相关的重点内容都讲完、讲透彻,请见谅。
一、前言
今天聊一聊 RPC 的相关内容,来看一下如何利用 Google 的开源序列化工具protobuf,来实现一个我们自己的 RPC 框架。
序列化[1]:将结构数据或对象转换成能够被存储和传输(例如网络传输)的格式,同时应当要保证这个序列化结果在之后(可能在另一个计算环境中)能够被重建回原来的结构数据或对象。
文章相关视频讲解(私信(Linux)我,获取学习链接):
Linux C/C++后台服务器开发高级架构师学习
高并发之protobuf通信协议设计.mp4
90分钟搞懂libevent网络库.mp4
90分钟搞懂网络编程的细节处理.mp4
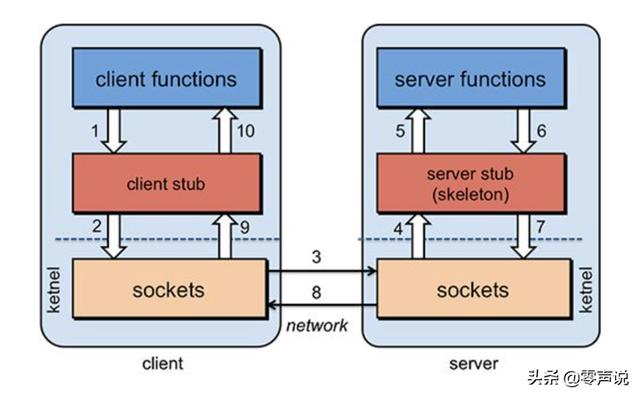
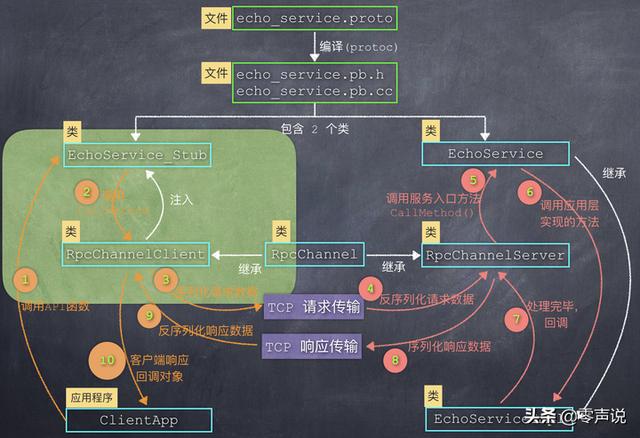
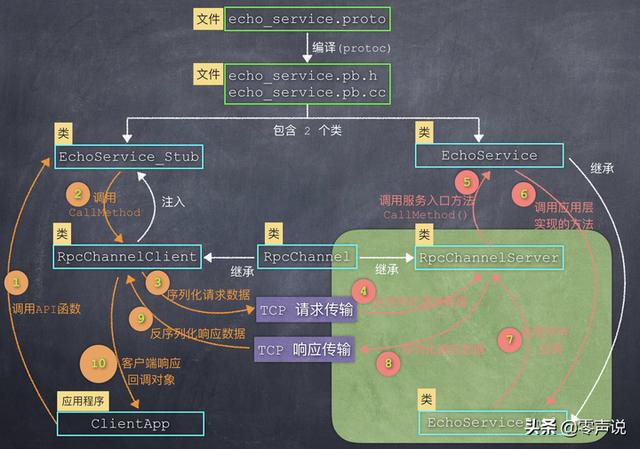
我会以 protobuf 中的一些关键 C++ 类作为突破口,来描述从客户端发起调用,到服务端响应,这个完整执行序列。 也就是下面这张图:

在下面的描述中,我会根据每一部分的主题,把这张图拆成不同的模块,从空间(文件和类的结构)和时间(函数的调用顺序、数据流向)这两个角度,来描述图中的每一个元素,我相信聪明的你一定会看明白的!
希望你看了这篇文章之后,对 RPC 框架的设计过程有一个基本的认识和理解,应对面试官的时候,关于 RPC 框架设计的问题应该绰绰有余了。
如果在项目中恰好选择了 protobuf,那么根据这张图中的模块结构和函数调用流程分析,可以协助你更好的完成每一个模块的开发。
注意:这篇文章不会聊什么内容:
protfobuf 的源码实现;
protfobuf 的编码算法;
二、RPC 基础概念
1. RPC 是什么?
RPC (Remote Procedure Call)从字面上理解,就是调用一个方法,但是这个方法不是运行在本地,而是运行在远程的服务器上。 也就是说,客户端应用可以像调用本地函数一样,直接调用运行在远程服务器上的方法。
下面这张图描述了 RPC 调用的基本流程:
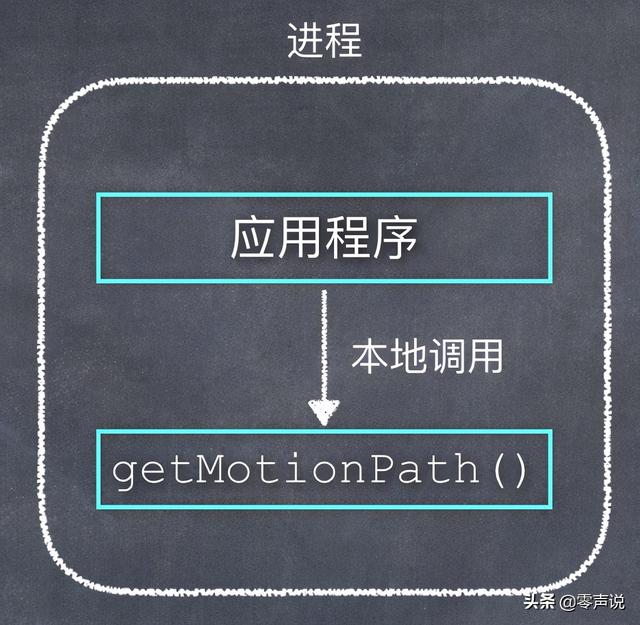
假如,我们的应用程序需要调用一个算法函数来获取运动轨迹:
int getMotionPath(float *input, int intputLen, float *output, int outputLen)
如果计算过程不复杂,可以把这个算法函数和应用程序放在本地的同一个进程中,以源代码或库的方式提供计算服务,如下图:
但是,如果这个计算过程比较复杂,需要耗费一定的资源(时间和空间),本地的 CPU 计算能力根本无法支撑,那么就可以把这个函数放在 CPU 能力更强的服务器上。
此时,调用过程如下图这样:
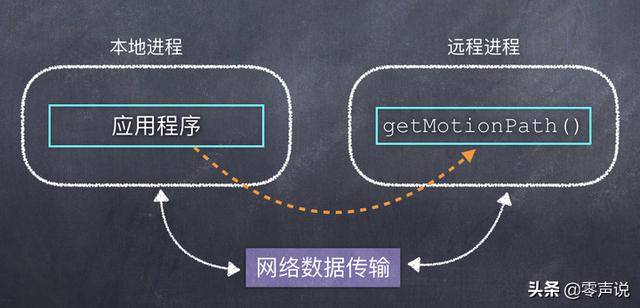
从功能上来看,应用程序仍然是调用远程服务器上的一个方法,也就是虚线部分。 但是由于他们运行在不同的实体设备上,更不是在同一个进程中,因此,如果想调用成功就一定需要利用网络来传输数据。
初步接触 RPC 的朋友可能会提出:
那我可以在应用程序中把算法需要的输入数据打包好,通过网络发送给算法服务器;服务器计算出结果后,再打包好返回给应用程序就可以了。
这句话说得非常对,从功能上来说,这个描述过程就是RPC 所需要做的所有事情。
不过,在这个过程中,有很多问题需要我们来手动解决:
如何处理通讯问题? TCP or UDP or HTTP? 或者利用其他的一些已有的网络协议?
如何把数据进行打包? 服务端接收到打包的数据之后,如何还原数据?
对于特定领域的问题,可以专门写一套实现来解决,但是对于通用的远程调用,怎么做到更灵活、更方便?
为了解决以上这几个问题,于是 RPC 远程调用框架就诞生了!
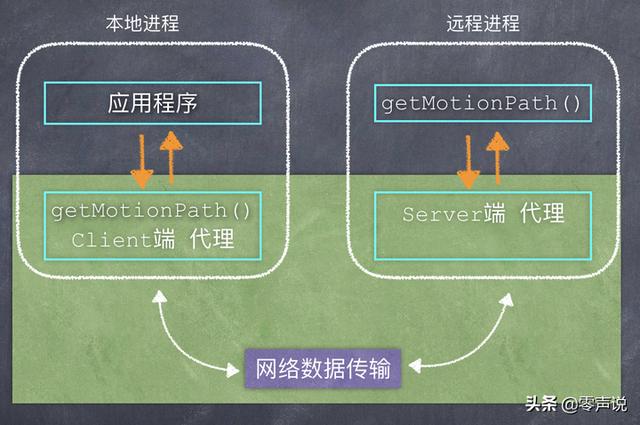
图中的绿色背景部分,就是 RPC 框架需要做的事情。
对于应用程序来说,Client 端代理就相当于是算法服务的「本地代理人」,至于这个代理人是怎么来处理刚才提到的那几个问题、然后从真正的算法服务器上得到结果,这就不需要应用程序来关心了。
结合文章的第一张图中,从应用程序的角度看,它只是执行了一个函数调用(步骤1),然后就立刻得到了结果(步骤10),这中间的所有步骤(2-9),全部是 RPC 框架来处理,而且能够灵活地处理各种不同的请求、响应数据。
铺垫到这里,我就可以更明确地再次重复一下了:这篇文章的目的,就是介绍如何利用 protobuf 来实现图中的绿色部分的功能。
最终的目的,将会输出一个RPC 远程调用框架的库文件(动态库、静态库):
服务器端利用这个库,在网络上提供函数调用服务;
客户端利用这个库,远程调用位于服务器上的函数;
2. 需要解决什么问题?
既然我们是介绍 RPC 框架,那么需要解决的问题就是一个典型的 RPC 框架所面对问题,如下:
解决函数调用时,数据结构的约定问题;
解决数据传输时,序列化和反序列化问题;
解决网络通信问题;
这 3 个问题是所有的 RPC 框架都必须解决的,这是最基本的问题,其他的考量因素就是:速度更快、成本更低、使用更灵活、易扩展、向后兼容、占用更少的系统资源等等。
另外还有一个考量因素:跨语言。 比如:客户端可以用C 语言实现,服务端可以用C/C++、Java或其他语言来实现,在技术选型时这也是非常重要的考虑因素。
3. 有哪些开源实现?
从上面的介绍中可以看出来,RPC 的最大优势就是降低了客户端的函数调用难度,调用远程的服务就好像在调用本地的一个函数一样。
因此,各种大厂都开发了自己的 RPC 框架,例如:
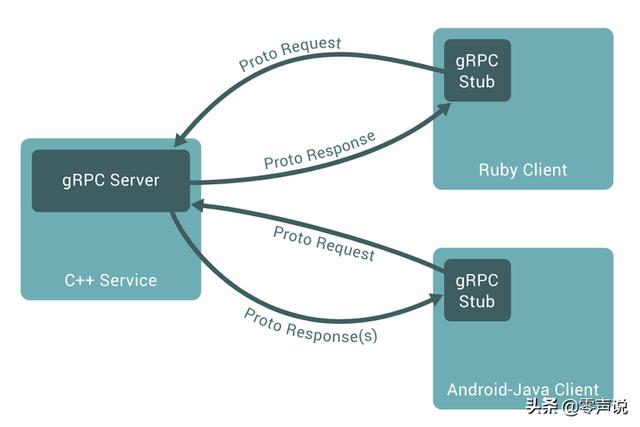
Google 的 gRPC;
Facebook 的 thrift;
腾讯的 Tars;
百度的 BRPC;
另外,还有很多小厂以及个人,也会发布一些 RPC 远程调用框架(tinyRPC,forestRPC,EasyRPC等等)。 每一家 RPC 的特点,感兴趣的小伙伴可以自行去搜索比对,这里对 gRPC 多说几句,
我们刚才主要聊了 protobuf,其实它只是解决了序列化的问题,对于一个完整的 RPC 框架,还缺少网络通讯这个步骤。
gRPC 就是利用了 protobuf,来实现了一个完整的 RPC 远程调用框架,其中的通讯部分,使用的是http协议。
文章福利 Linux后端开发网络底层原理知识学习提升,私信(Linux),完善技术栈,内容知识点包括Linux,Nginx,ZeroMQ,MySQL,Redis,线程池,MongoDB,ZK,Linux内核,CDN,P2P,epoll,Docker,TCP/IP,协程,DPDK等等。
三、protobuf 基本使用
1.基本知识
Protobuf是Protocol Buffers的简称,它是 Google 开发的一种跨语言、跨平台、可扩展的用于序列化数据协议,
Protobuf 可以用于结构化数据序列化(串行化),它序列化出来的数据量少,再加上以 K-V 的方式来存储数据,非常适用于在网络通讯中的数据载体。
只要遵守一些简单的使用规则,可以做到非常好的兼容性和扩展性,可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
Protobuf 中最基本的数据单元是message,并且在message中可以多层嵌套message或其它的基础数据类型的成员。
Protobuf 是一种灵活,高效,自动化机制的结构数据序列化方法,可模拟 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更简单,而且它支持 Java、C++、Python 等多种语言。
2. 使用步骤
Step1:创建 .proto 文件,定义数据结构
例如,定义文档, 其中的内容为: echo_service.proto
message EchoRequest {
string message = 1;
}
message EchoResponse {
string message = 1;
}
message AddRequest {
int32 a = 1;
int32 b = 2;
}
message AddResponse {
int32 result = 1;
}
service EchoService {
rpc Echo(EchoRequest) returns(EchoResponse);
rpc Add(AddRequest) returns(AddResponse);
}
最后的 ,是让 protoc 生成接口类,其中包括 2 个方法Echo 和 Add:service EchoService
Echo 方法:客户端调用这个方法,请求的「数据结构」 EchoRequest 中包含一个 string 类型,也就是一串字符;服务端返回的「数据结构」 EchoResponse 中也是一个 string 字符串; Add 方法:客户端调用这个方法,请求的「数据结构」 AddRequest 中包含 2 个整型数据,服务端返回的「数据结构」 AddResponse 中包含一个整型数据(计算结果);
Step2: 使用 protoc 工具,编译 .proto 文档,生成界面(类以及相应的方法)
protoc echo_service.proto -I./ --cpp_out=./
执行以上命令,即可生成两个文件:,在这2个文件中,定义了2个重要的类,也就是下图中绿色部分:echo_service.pb.h, echo_service.pb.c
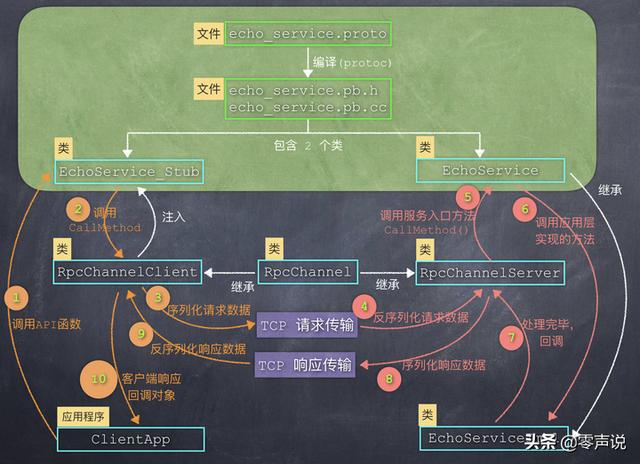
EchoService 和EchoService_Stub这 2 个类就是接下来要介绍的重点。 我把其中比较重要的内容摘抄如下(为减少干扰,把命名空间字符都去掉了):
class EchoService : public ::PROTOBUF_NAMESPACE_ID::Service {
virtual void Echo(RpcController* controller,
EchoRequest* request,
EchoResponse* response,
Closure* done);
virtual void Add(RpcController* controller,
AddRequest* request,
AddResponse* response,
Closure* done);
void CallMethod(MethodDescriptor* method,
RpcController* controller,
Message* request,
Message* response,
Closure* done);
}class EchoService_Stub : public EchoService {
public:
EchoService_Stub(RpcChannel* channel);
void Echo(RpcController* controller,
EchoRequest* request,
EchoResponse* response,
Closure* done);
void Add(RpcController* controller,
AddRequest* request,
AddResponse* response,
Closure* done);
private:
// 成員變數,比較關鍵
RpcChannel* channel_;
};
Step3:服务端程序实现接口中定义的方法,提供服务;客户端调用接口函数,调用远程的服务。
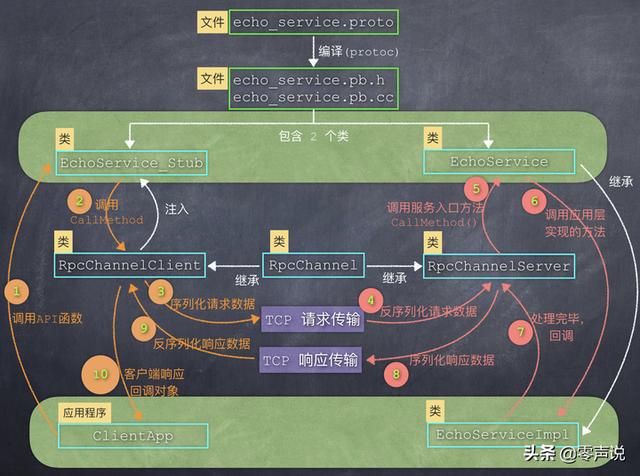
请关注上图中的绿色部分。
(1)服务端:EchoService
EchoService类中的两个方法 Echo 和 Add 都是虚函数,我们需要继承这个类,定义一个业务层的服务类 EchoServiceImpl,然后实现这两个方法,以此来提供远程调用服务。
EchoService 类中也给出了这两个函数的默认实现,只不过是提示错误信息:
void EchoService::Echo() {
controller->SetFailed("Method Echo() not implemented.");
done->Run();
}void EchoService::Add() {
controller->SetFailed("Method Add() not implemented.");
done->Run();
}
图中的EchoServiceImpl就是我们定义的类,其中实现了 Echo 和 Add 这两个虚函数:
void EchoServiceImpl::Echo(RpcController* controller,
EchoRequest* request,
EchoResponse* response,
Closure* done)
{
// 获取请求消息,然后在末尾加上资讯:", welcome!",返回給客戶端
response->set_message(request->message() + ", welcome!");
done->Run();
}
void EchoServiceImpl::Add(RpcController* controller,
AddRequest* request,
AddResponse* response,
Closure* done)
{
// 获取请求数据中的 2 个整型数据
int32_t a = request->a();
int32_t b = request->b();
// 计算结果,然后放入响应数据中
response->set_result(a + b);
done->Run();
}
(2)客户端:EchoService_Stub
EchoService_Stub就相当于是客户端的代理,应用程序只要把它"当做"远程服务的替身,直接调用其中的函数就可以了(图中左侧的步骤1)。
因此,EchoService_Stub此类中肯定要实现 Echo 和 Add 这 2 个方法,看一下 protobuf自动生成的实现代码:
void EchoService_Stub::Echo(RpcController* controller,
EchoRequest* request,
EchoResponse* response,
Closure* done) {
channel_->CallMethod(descriptor()->method(0),
controller,
request,
response,
done);
}
void EchoService_Stub::Add(RpcController* controller,
AddRequest* request,
AddResponse* response,
Closure* done) {
channel_->CallMethod(descriptor()->method(1),
controller,
request,
response,
done);
}
看到没,每一个函数都调用了成员变量 channel_ 的 CallMethod 方法(图中左侧的步骤2),这个成员变量的类型是google::p rotobuf:RpcChannel。
从字面上理解:channel 就像一个通道,是用来解决数据传输问题的。 也就是说方法会把所有的数据结构序列化之后,通过网络发送给服务器。channel_->CallMethod
既然 RpcChannel 是用来解决网络通信问题的,因此客户端和服务端都需要它们来提供数据的接收和发送。
图中的是客户端使用的 Channel, 是服务端使用的 Channel,它俩都是继承自 protobuf 提供的。RpcChannelClientRpcChannelServer RpcChannel

注意:这里的,只是提供了网络通讯的策略,至于通讯的机制是什么(TCP? UDP? http?),protobuf并不关心,这需要由RPC框架来决定和实现。 RpcChannel
protobuf 提供了一个基类,其中定义了方法。 我们的 RPC 框架中,客户端和服务端实现的 Channel必须继承protobuf 中的,然后重载这个方法。 RpcChannelCallMethod RpcChannelCallMethod
CallMethod 方法的几个参数特别重要,我们通过这些参数,来利用 protobuf 实现序列化、控制函数调用等操作,也就是说这些参数就是一个纽带,把我们写的代码与 protobuf 提供的功能,连接在一起。
我们这里选了这个网络库来实现 TCP 通讯。libevent
四、libevent
实现 RPC 框架,需要解决 2 个问题:通信和序列化。 protobuf 解决了序列化问题,那么还需要解决通讯问题。
有下面几种通信方式备选:
TCP 通讯;
UDP 通讯;
HTTP 通讯;
如何选择,那就是见仁见智的事情了,比如 gRPC 选择的就是http,也工作得很好,更多的实现选择的是TCP通讯。
下面就是要决定:是从 socket 层次开始自己写? 还是利用已有的一些开源网络库来实现通讯?
既然标题已经是 libevent 了,那肯定选择的就是它! 当然还有很多其他优秀的网络库可以利用,比如:libev, libuv 等等。
1. libevent 简介
Libevent 是一个用C 语言编写的、轻量级、高性能、基于事件的网络库。
主要有以下几个亮点:
事件驱动( event-driven),高性能; 轻量级,专注于网络;源代码相当精炼、易读; 跨平台,支持 Windows、 Linux、*BSD 和 Mac Os; 支持多种 I/O 多路复用技术, epoll、 poll、 dev/poll、 select 和 kqueue 等; 支持 I/O,定时器和信号等事件;注册事件优先顺序。
从我们用户的角度来看,libevent 库提供了以下功能:当一个文件描述符的特定事件(如可读,可写或出错)发生了,或一个定时事件发生了, libevent 就会自动执行用户注册的回调函数,来接收数据或者处理事件。
此外,libevent 还把 fd 读写、信号、DNS、定时器甚至idle(空闲) 都抽象化成了event(事件)。
总之一句话:使用很方便,功能很强大!
2.基本使用
libevent 是基于事件的回调函数机制,因此在启动监听 socket 之前,只要设置好相应的回调函数,当有事件或者网络数据到来时,libevent 就会自动调用回调函数。
struct event_base *m_evBase = event_base_new();
struct bufferevent *m_evBufferEvent = bufferevent_socket_new(
m_evBase, [socket Id],
BEV_OPT_CLOSE_ON_FREE | BEV_OPT_THREADSAFE);
bufferevent_setcb(m_evBufferEvent,
[读取数据回调函数],
NULL,
[事件回调函数],
[回调函数传参]);
// 开始监听 socket
event_base_dispatch(m_evBase);
有一个问题需要注意:protobuf 序列化之后的数据,全部是二进制的。
libevent 只是一个网络通讯的机制,如何处理接收到的二进制数据(粘包、分包的问题),是我们需要解决的问题。
文章福利 Linux后端开发网络底层原理知识学习提升,私信(Linux),完善技术栈,内容知识点包括Linux,Nginx,ZeroMQ,MySQL,Redis,线程池,MongoDB,ZK,Linux内核,CDN,P2P,epoll,Docker,TCP/IP,协程,DPDK等等。
五、实现 RPC 框架
从刚才的第三部分: 自动生成的几个类中,已经能够大概看到 RPC 框架的端倪了。 这里我们再整合在一起,看一下更具体的细节部分。EchoService, EchoService_Stub
1. 基本框架构思
我把图中的干扰细节全部去掉,得到下面这张图:

其中的绿色部分就是我们的 RPC 框架需要实现的部分,功能简述如下:
EchoService:服务端界面类,定义需要实现哪些方法;
EchoService_Stub: 继承自 EchoService,是客户端的本地代理;
RpcChannelClient: 用户处理客户端网络通讯,继承自 RpcChannel;
RpcChannelServer: 用户处理服务端网络通讯,继承自 RpcChannel;
应用程序 :
EchoServiceImpl:服务端应用层需要实现的类,继承自 EchoService;
ClientApp: 客户端应用程序,调用 EchoService_Stub 中的方法;
2.元数据的设计
在echo_servcie.proto文件中,我们按照 protobuf 的语法规则,定义了几个 Message,可以看作是"数据结构」:
Echo 方法相关的「数据结构」:EchoRequest, EchoResponse。 Add 方法相关的「数据结构」:AddRequest, AddResponse。
这几个数据结构是直接与业务层相关的,是我们的客户端和服务端来处理请求和响应数据的一种约定。
为了实现一个基本完善的数据 RPC 框架,我们还需要其他的一些「数据结构」来完成必要的功能,例如:
调用 Id 管理;
错误处理;
同步调用和异步调用;
超时控制;
另外,在调用函数时,请求和响应的「数据结构」是不同的数据类型。 为了便于统一处理,我们把请求数据和响应数据都包装在一个统一的 RPC 「数据结构」中,并用一个类型字段(type)来区分:某个 RPC 消息是请求数据,还是响应数据。
根据以上这些想法,我们设计出下面这样的元数据:
// 消息类型
enum MessageType
{
RPC_TYPE_UNKNOWN = 0;
RPC_TYPE_REQUEST = 1;
RPC_TYPE_RESPONSE = 2;
RPC_TYPE_ERROR = 3;
}
// 错误程式码
enum ErrorCode
{
RPC_ERR_OK = 0;
RPC_ERR_NO_SERVICE = 1;
RPC_ERR_NO_METHOD = 2;
RPC_ERR_INVALID_REQUEST = 3;
RPC_ERR_INVALID_RESPONSE = 4
}
message RpcMessage
{
MessageType type = 1; // 消息类型
uint64 id = 2; // 消息id
string service = 3; // 服务名称
string method = 4; // 方法名称
ErrorCode error = 5; // 错误程式码
bytes request = 100; // 请求数据
bytes response = 101; // 响应数据
}
注意:这里的 request 和 response,它们类型都是 byte。
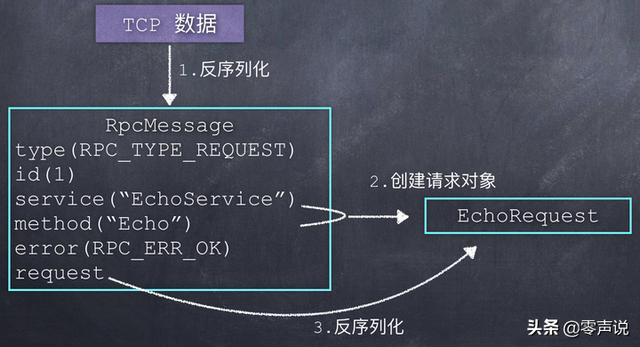
客户端在发送数据时:
首先,构造一个 RpcMessage 变数,填入各种元数据(type, id, service, method, error); 然后,序列化客户端传入的请求对象(EchoRequest), 得到请求数据的字节码; 再然后,把请求数据的字节插入到RpcMessage中的request字段; 最后,把RpcMessage变量序列化之后,通过TCP发送出去。
如下图:

服务端在接收到 TCP 数据时,执行相反的操作:
首先,把接收到的 TCP 数据反序列化,得到一个 RpcMessage 变数; 然后,根据其中的 type 字段,得知这是一个调用请求,于是根据 service 和 method 字位,构造出两个类实例:EchoRequest 和 EchoResponse(利用了 C++ 中的原型模式); 最后,从RpcMessage消息中的request字位反序列化,来填充EchoRequest实例;
这样就得到了这次调用请求的所有数据。 如下图:
3. 客户端发送请求数据
这部分主要描述下图中绿色部分的内容:
Step1: 业务级客户端调用 Echo() 函数
// ip, port 是服務端網路地址
RpcChannel *rpcChannel = new RpcChannelClient(ip, port);
EchoService_Stub *serviceStub = new EchoService_Stub(rpcChannel);
serviceStub->Echo(...);
上文已经说过,EchoService_Stub中的 Echo 方法,会调用其成员变量 channel_ 的 CallMethod方法,因此,需要提前把实现好的RpcChannelClient实例,作为构造函数的参数,注册到 EchoService_Stub中。
Step2: EchoService_Stub 调用 channel_. CallMethod() 方法
这个方法在RpcChannelClient (继承自 protobuf 中的 RpcChannel 类)中实现,它主要的任务就是:把 EchoRequest 请求数据,包装在 RPC 元数据中,然后序列化得到二进制数据。
// 创建 RpcMessage
RpcMessage message;
// 填充元数据
message.set_type(RPC_TYPE_REQUEST);
message.set_id(1);
message.set_service("EchoService");
message.set_method("Echo");
// 序列化请求变数,填充 request 栏位
// (这里的 request 变数,是客户端程式传进来的)
message.set_request(request->SerializeAsString());
// 把 RpcMessage 序列化
std::string message_str;
message.SerializeToString(&message_str);
Step3: 通过 libevent 接口函数发送 TCP 数据
bufferevent_write(m_evBufferEvent, [二进位数据]);
4. 服务端接收请求数据
这部分主要描述下图中绿色部分的内容:

Step4: 第一次反序列化数据
RpcChannelServer是负责处理服务端的网络数据,当它接收到 TCP 数据之后,首先进行第一次反序列化,得到 RpcMessage 变量,这样就获得了 RPC 元数据,包括:消息类型(请求RPC_TYPE_REQUEST)、消息 Id、Service 名称("EchoServcie")、Method 名称("Echo")。
RpcMessage rpcMsg;
// 第一次反序列化
rpcMsg.ParseFromString(tcpData);
// 创建请求和响应实例
auto *serviceDesc = service->GetDescriptor();
auto *methodDesc = serviceDesc->FindMethodByName(rpcMsg.method());
从请求数据中获取到请求服务的Service名称(serviceDesc)之后,就可以查找到服务对象EchoService了,因为我们也拿到了请求方法的名称(methodDesc),此时利用 C++ 中的原型模式,构造出这个方法所需要的请求对象和响应对象,如下:
// 构造 request & response 对象
auto *echoRequest = service->GetRequestPrototype(methodDesc).New();
auto *echoResponse = service->GetResponsePrototype(methodDesc).New();
构造出请求对象 echoRequest 之后,就可以用 TCP 数据中的请求字段(即: rpcMsg.request)来第二次反序列化了,此时就还原出了这次方法调用中的参数,如下:
// 第二次反序列化:
request->ParseFromString(rpcMsg.request());
这里有一个内容需要补充一下: EchoService 服务是如何被查找到的?
在服务端可能同时运行了很多个Service 以提供不同的服务,我们的 EchoService 只是其中的服务之一。 那么这就需要解决一个问题:在从请求数据中提取出 Service 和 Method 的名称之后,如何找到 EchoService 实例?
一般的做法是:在服务端有一个Service 服务对象池,当 RpcChannelServer 接收到调用请求后,到这个池子中查找相应的 Service 对象,对于我们的示例来说,就是要查找 EchoServcie 对象,例如:
std::map<std::string, google::protobuf::Service *> m_spServiceMap;
// 服务端启动的时候,把一个 EchoServcie 实例注册到池子中
EchoService *echoService = new EchoServiceImpl();
m_spServiceMap->insert("EchoService", echoService);
由于示例已经提前创建好,并注册到 Service 对象池中(以名称字符串作为关键字),因此当需要的时候,就可以通过服务名称来查找相应的服务对象了。EchoService
Step5: 调用 EchoServiceImpl 中的 Echo() 方法
查找到服务对象之后,就可以调用其中的 Echo() 这个方法了,但不是直接调用,而是用一个中间函数来进行过渡。EchoServiceCallMethod
// 查找到 EchoService 对象
service->CallMethod(...)
在echo_servcie.pb.cc中,这个 CallMethod() 方法的实现为:
void EchoService::CallMethod(...)
{
switch(method->index())
{
case 0:
Echo(...);
break;
case 1:
Add(...);
break;
}
}
可以看到:protobuf 是利用固定(写死)的索引,来定位一个 Service 服务中所有的 method 的,也就是说顺序很重要!
Step6: 调用 EchoServiceImpl 中的 Echo 方法
EchoServiceImpl 类继承自,并实现了其中的虚函数 Echo 和 Add,因此 Step5 正在调用 Echo 方法时,根据 C++ 的多态,就进入了业务层中实现的 Echo 方法。 EchoService
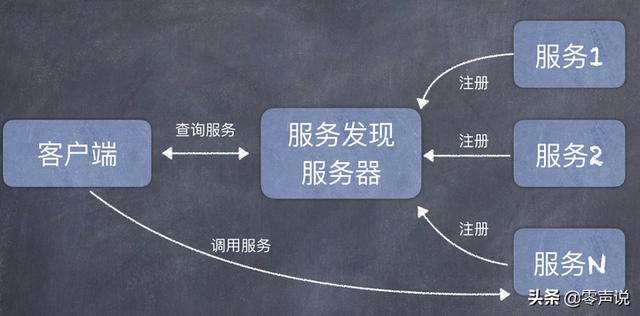
再补充另一个知识点:我们这里的示例代码中,客户端是预先知道服务端的 IP 地址和端口号的,所以就直接建立到服务器的 TCP 连接了。 在一些分布式应用场景中,可能会有一个服务发现流程。 也就是说:每一个服务都注册到「服务发现服务器」上,然后客户端在调用远程服务的之前,并不知道服务提供商在什么位置。 客户端首先到服务发现服务器中查询,拿到了某个服务提供者的网络地址之后,再向该服务提供者发送远程调用请求。
当查找到EchoServcie服务对象之后,就可以调用其中的指定方法了。
5. 服务端发送响应数据
这部分主要描述下图中绿色部分的内容:
Step7: 业务层处理完毕,回调 RpcChannelServer 中的回调对象
在上面的 Step4 中,我们通过原型模式构造了 2 个对象:请求对象(echoRequest)和响应对象(echoResponse),代码重贴一下:
// 构造 request & response 对象
auto *echoRequest = service->GetRequestPrototype(methodDesc).New();
auto *echoResponse = service->GetResponsePrototype(methodDesc).New();
构造 echoRequest 对象比较好理解,因为我们要从 TCP 二进制数据中反序列化,得到 Echo 方法的请求参数。
那么 echoResponse 这个对象为什么需要构造出来? 这个对象的目的肯定是为了存放处理结果。
在Step5中,调用的时候,传递参数如下:service->CallMethod(…)
service->CallMethod([参数1:先不管], [参数2:先不管], echoRequest, echoResponse, respDone);
// this position
按照一般的函数调用流程,在中调用 Echo() 函数,业务层处理完之后,会回到上面 这个位置。 然后再把 echoResponse 响应数据序列化,最后通过 TCP 发送出去。CallMethodthis position
但是 protobuf 的设计并不是如此,这里利用了 C++ 中的闭包的可调用特性,构造了respDone这个变量,这个变量会一直作为参数传递到业务层的 Echo() 方法中。
这个对象是这样创建出来的:respDone
auto respDone = google::protobuf::NewCallback(this, &RpcChannelServer::onResponseDoneCB, echoResponse);
这里的,是由 protobuf 提供的,在 protobuf 源码中,有这么一段: NewCallback
template <typename Class, typename Arg1>
inline Closure* NewPermanentCallback(Class* object,
void (Class::*method)(Arg1),
Arg1 arg1) {
return new internal::MethodClosure1<Class, Arg1>(object, method, false, arg1);
}
// 只贴出关键程式码
class MethodClosure1 : public Closure
{
void Run() override
{
(object_->*method_)(arg1_);
}
}
因此,通过NewCallBack这个模板方法,就可以创建一个可调用对象respDone,并且这个对象中保存了传入的参数:一个函数,这个函数接收的参数。
当在以后某个时候,调用respDone这个对象的 Run 方法时,这个方法就会调用它保存的那个函数,并且传入保存的参数。
有了这部分知识,再来看一下业务层的 Echo() 代码 :
void EchoServiceImpl::Echo(protobuf::RpcController* controller,
EchoRequest* request,
EchoResponse* response,
protobuf::Closure* done)
{
response->set_message(request->message() + ", welcome!");
done->Run();
}
可以看到,在Echo 方法处理完毕之后,只调用了方法,这个方法会调用之前作为参数注册进去的 方法,并且把响应对象作为参数传递进去。done->Run()RpcChannelServer::onResponseDoneCB echoResponse
这这里就比较好理解了,可以预见到:方法中一定是进行了 2 个操作:RpcChannelServer::onResponseDoneCB
反序列化数据;
发送TCP数据;
Step8: 序列化得到二进制字节码,发送TCP数据
首先,构造 RPC 元数据,把响应对象序列化之后,设置到 response 字段。
void RpcChannelImpl::onResponseDoneCB(Message *response)
{
// 构造外层的 RPC 元数据
RpcMessage rpcMsg;
rpcMsg.set_type(RPC_TYPE_RESPONSE);
rpcMsg.set_id([消息 Id]]);
rpcMsg.set_error(RPC_ERR_SUCCESS);
// 把响应对象序列化,设置到 response 栏位。
rpcMsg.set_response(response->SerializeAsString());
}
然后,序列化数据,通过libevent发送TCP数据。
std::string message_str;
rpcMsg.SerializeToString(&message_str);
bufferevent_write(m_evBufferEvent, message_str.c_str(), message_str.size());
6. 客户端接收响应数据
这部分主要描述下图中绿色部分的内容:
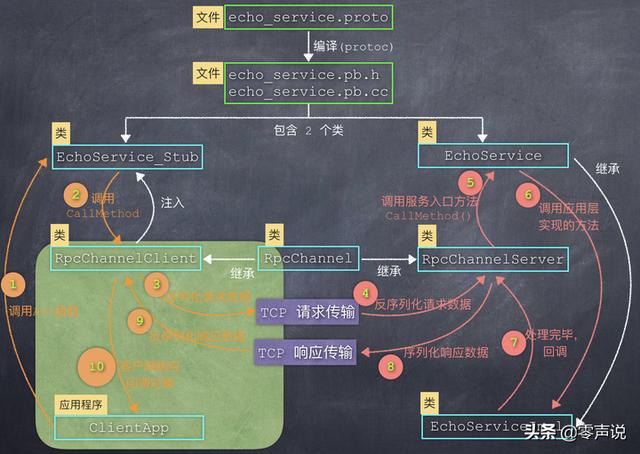
Step9: 反序列化接收到的 TCP 数据
RpcChannelClient 是负责客户端的网络通讯,因此当它接收到 TCP 数据之后,首先进行第一次反序列化,构造出 RpcMessage 变量,其中的 response 栏位就存放着服务端的函数处理结果,只不过此时它是二进制数据。
RpcMessage rpcMsg;
rpcMsg.ParseFromString(tcpData);
// 此时,rpcMsg.reponse 中存储的就是 Echo() 函数处理结果的二进位数据。
Step10: 调用业务层客户端的函数来处理 RPC 结果
那么应该把这个二进制响应数据序列化到哪一个 response 对象上呢?
在前面的主题【客户端发送请求数据】,也就是 Step1 中,业务层客户端在调用 方法的时候,我没有列出传递的参数,这里把它补全:serviceStub->Echo(…)
// 定义请求对象
EchoRequest request;
request.set_message("hello, I am client");
// 定义响应对象
EchoResponse *response = new EchoResponse;
auto doneClosure = protobuf::NewCallback(
&doneEchoResponseCB,
response
);
// 第一个参数先不用关心
serviceStub->Echo(rpcController, &request, response, doneClosure);
可以看到,这里同样利用了 protobuf 提供的NewCallback模板方法,来创建一个可调用对象(闭包doneClosure),并且让这个闭包保存了 2 个参数:一个回调函数(doneEchoResponseCB)和response 对象(应该说是指针更准确)。
当回调函数doneEchoResponseCB被调用的时候,会自动把response对象作为参数传递进去。
这个可调用对象(doneClosure闭包) 和 response 对象,被作为参数一路传递到 EchoService_Stub –> RpcChannelClient,如下图所示:
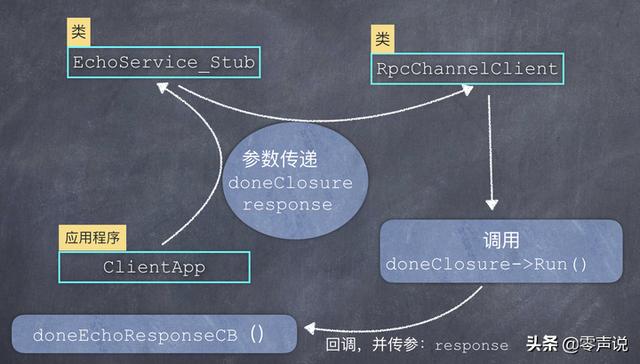
因此当RpcChannelClient接收到 RPC 远程调用结果时,就把二进位的 TCP 数据,反序列化到response对象上,然后再调用doneClosure->Run()方法,Run() 方法中执行 ,就调用了业务层中的回调函数,也把参数传递进去了。 (object_->*method_)(arg1_)
业务层的回调函数doneEchoResponseCB()函数的代码如下:
void doneEchoResponseCB(EchoResponse *response)
{
cout << "response.message = " << response->message() << endl;
delete response;
}
至此,整个RPC调用流程结束。
六、总结
1. protobuf 的核心
通过以上的分析,可以看出 protobuf 主要是为我们解决了序列化和反序列化的问题。
然后又通过RpcChannel这个类,来完成业务层的用户代码与protobuf 代码的整合问题。
利用这两个神器,我们来实现自己的 RPC 框架,思路就非常的清晰了。
2. 未解决的问题
这篇文章仅仅是分析了利用 protobuf 工具,来实现一个 RPC 远程调用框架中的几个关键的类,以及函数的调用顺序。
按照文中的描述,可以实现出一个满足基本功能的 RPC 框架,但是还不足以在产品中使用,因为还有下面几个问题需要解决:
同步调用和异步调用问题;
并发问题(多个客户端的并发连接,同一个客户端的并发调用);
调用超时控制;
以后有机会的话,再和大家一起继续深入地讨论这些话题,祝您好运!