
智东西(公众号:zhidxcom)
作者 | 心缘
编辑 | 漠影
智东西6月1日报道,上午,在聚集了200余位国内外顶尖AI专家的2021北京智源大会开幕式上,北京智源人工智能研究院发布全球最大预训练模型——“悟道2.0”巨模型,参数量高达1.75万亿!
北京智源大会是由智源研究院主办的年度国际性AI高端学术交流会议,定位于“内行的AI顶级会议”,旨在成为北京乃至中国AI发展的学术名片。
而此次重磅发布的“悟道2.0”巨模型,是中国首个全球最大万亿模型,比有1.6万亿个参数的谷歌最大模型Switch Transformer,足足多了1500亿个参数;是OpenAI GPT-3模型参数量的10倍。
此外,“悟道2.0”还取得多项世界级创新突破,在预训练模型架构、微调算法、⾼效预训练框架等⽅面实现了原始理论创新,并在世界公认的AI能⼒排名榜单上,取得9项能⼒的领先地位。
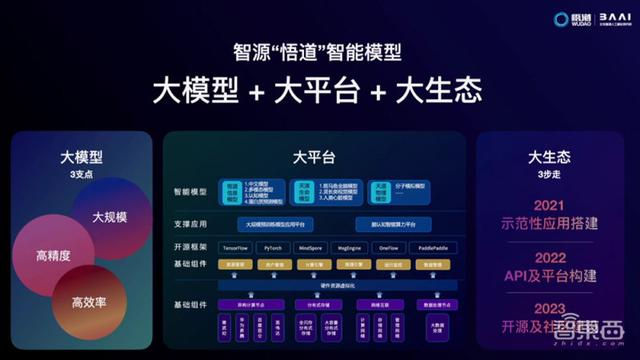
智源“悟道”智能模型:大模型+大平台+大生态
尤其值得⼀提的是,这个由智源副院⻓、清华⼤学教授唐杰率领中国科学家团队联合攻关的万亿模型,首次100%基于国产超算平台打造、运⽤中国技术,打破原来只能用GPU训练模型的问题。
智源研究院还与新华社战略合作,将悟道模型应用于新闻数字化转型;并合作智谱AI、微软小冰公司,联合培养准备进入清华唐杰实验室的中国首位原创虚拟学生“华智冰”。

中国首位原创虚拟学生“华智冰”:基于“悟道2.0”大模型和小冰框架的AI内容生成技术生成
这一技术现已开源,任何个人或企业即日起可免费申请使用公开API:
https://wudaoai.cn/home
一、万亿模型新里程碑,9项顶尖AI能力
这个全球最大、中国首个万亿参数的双语多模态模型,究竟能做什么?
悟道同时支持NLP理解、生成任务与文生图、图生文任务。简单来说,从作诗写文、对联问答到配图猜图、绘画设计,它都能与人类一较高下。
在世界公认的9项Benchmark上,悟道2.0均取得了顶尖能力水平,达到了精准智能。

悟道2.0在9项Benchmark上取得的新成就
以悟道模型包含的全球最大中文多模态生成模型CogView为例,这个模型有40亿个参数,代表了世界顶尖的⽂图绘画能⼒。
CogView克服了做文图模型在半精度下因为上下溢无法正常收敛的关键问题,也是继DALL·E之后少有的通⽤领域⽂图模型。

CogView:精度最高的通用领域文图模型
在MS COCO文本生成图像任务权威指标FID上,CogView打败OpenAI拥有130亿参数的DALL·E模型,获得世界第一。
给一段符合现实场景或者天马行空的话,比如“金发女郎打电话”、“素描房子”,或者“老虎踢足球”、“一个人在月球上骑自行车”,CogView都能创作出相应的图像。

生成符合句子含义的图像
CogView也能直接实现类似于OpenAI CLIP模型的⾃评分功能,且画风多元,中国画、卡通画、轮廓画、油画等等都能生成。

生成各种风格的“东方明珠”
CogView还能充当设计师。比如,通过与阿⾥巴巴达摩院智能计算组合作,CogView经过GAN的增强后,应⽤到阿⾥的服饰设计业务。

将CogView经过GAN增强后应用到阿里的服饰设计业务
或许,你的购物⻋里,就躺着“悟道”的设计。
如果说CogView展现了AI的最佳实际作画能⼒,神经元可视化技术,则突破想象地描绘出AI的梦境——对于⼀个给定的文本概念,得到与其特征表示最为接近的图像可视化。
从如下图示,多模态预训练后的神经⽹络已经能“看到”抽象的人类概念。

生成“圣诞”、“梦境”等抽象概念
AI的想象世界,也许有人类手笔所无法触碰的美轮美奂。
除了按字生图外,悟道也能实现根据图片来生成描述图片内容的流畅语句,并能预测每个动画图像的准确标签,大大提高图像标记任务的效率,这给自动生成字幕、将图片与对应“金句”、歌词相匹配等应用带来便利。

理解图像信息并提炼关键标签
目前,悟道多项应用正在逼近突破图灵测试。

二、为什么“全球最大”模型,会出现在智源?
“悟道”攻关团队由智源副院⻓、清华⼤学教授唐杰领衔,清华、北大、⼈大、中科院等100余位科学家联合攻关,形成了AI的特战团队。
今年3月20日,智源研究院发布我国首个超大规模智能模型“悟道1.0”,包含中文、多模态、认知、蛋白质预测在内的系列模型,取得了多项国际领先的AI技术突破。

“悟道2.0”超大规模预训练模型阵容及最新成果
这一项目的启动,要追溯到2020年6月。当时OpenAI拥有1750亿个参数的超大规模语言模型GPT-3横空出世,火速红遍全球AI圈。
在接受智东西专访时,智源研究院理事长张宏江评价说:“GPT-3的诞生,标志着AI已经从过去15年发展中的算法突破,进入大系统的突破。”
预见到大模型的里程碑意义后,智源的核心成员迅速做了一番研究,判断这对中国AI产业至关重要。经过与产学政多方交流,智源随即做出决策并组建团队,专攻大模型。
研发大模型绝非易事,超大规模算力、足质足量的数据、算法根基深厚的学者缺一不可。
而介乎于产学政之间的智源研究院,恰恰具备高效整合这些资源的能力。这也是为什么,智源团队在短短几个月内,即创下“悟道”巨模型的新纪录。
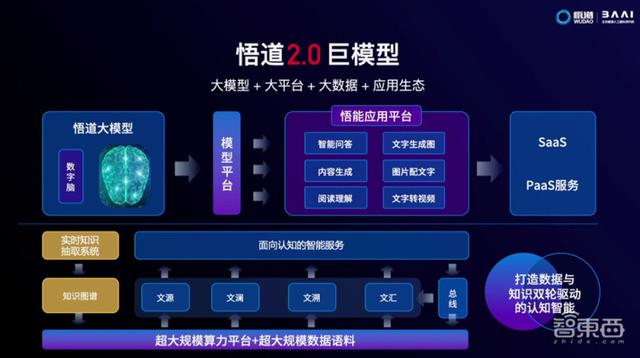
“悟道2.0”巨模型
“悟道”万亿模型一统文本与视觉两大阵地,支持中英双语,在共4.9T的高质量清洗数据上训练。
从技术突破来看,悟道·文汇基于GLM+CogView+FastMoE技术,CogView已经在前文聊过,GLM2.0、FastMoE技术也都值得一提。
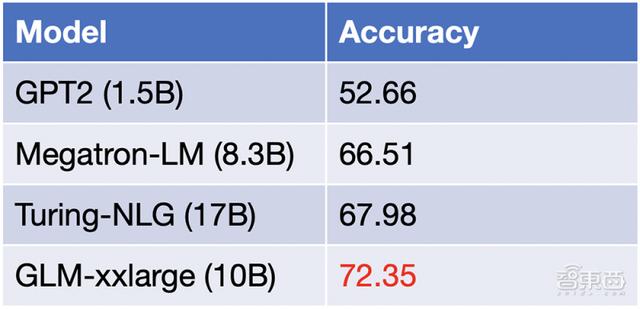
最大的英文通用预训练模型GLM2.0曾首次打破BERT和GPT壁垒,开创性地以单⼀模型兼容所有主流架构。
新⼀代版本更是模型创新、以少胜多的高性能AI典范:以100亿参数量,足以匹敌微软170亿参数的Turing-NLG模型,取得多项任务的更优成绩。
开创性的FastMoE技术,是打破国外技术瓶颈,实现“万亿模型”基石的关键。
此前因谷歌万亿模型的核心参数MoE(Mixture of Experts)和其昂贵的硬件强绑定,绝⼤多数⼈无法得到使用与研究机会。
MoE是⼀个在神经网络中引入若⼲专家⽹络(Expert Network)的技术,能直接推动预训练模型经从亿级参数到万亿级参数的跨越,但它离不开对谷歌分布式训练框架mesh-tensorflow和谷歌定制硬件TPU的依赖。
而FastMoE打破了这⼀限制:作为首个支持PyTorch框架的MoE系统,它简单易用、灵活、⾼性能,且⽀持大规模并行训练。
FastMoE由“悟道文汇”和“悟道文溯”两个研究小组联合攻关,可在不同规模的计算机或集群上支持探索不同的MoE模型在不同领域的应用,相比直接使用PyTorch实现的版本,提速47倍。
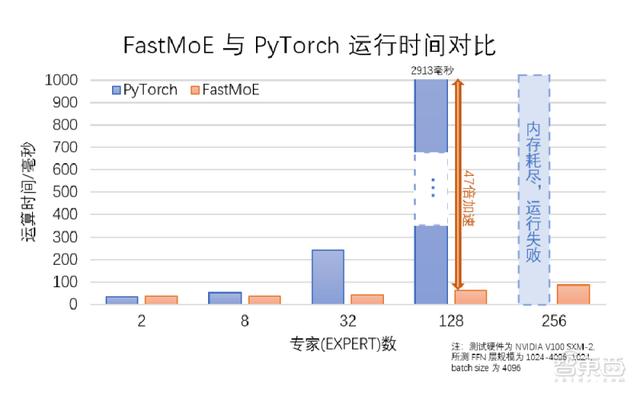
单GPU多experts情况下,FastMoE相比普通PyTorch实现的加速比
新一代FastMoE支持Switch、GShard等复杂均衡策略,⽀持不同专家不同模型,最大测试了几万个专家的MoE训练。
FastMoE已基于阿里PAI平台,探索在支付宝智能化服务体系中的应用;亦在国产神威众核超算平台成功部署。
目前该技术已经开源,这为万亿模型实现⽅案补上了最后⼀块短板。
此外,智源提出FewNLU小样本学习系统,在小样本学习自然语言理解任务上实现新SOTA,极大缩小了与全监督学习条件下微调性能的差距。
其中包含的P-tuning 2.0算法,历史上首次实现自回归模型在理解任务上超越自编码模型,极大拉近少样本学习和全监督学习的差距,少样本学习能力遥遥领先。

“悟道”攻关团队成员
三、高效易用,全部开源
“⾼效易用”是“悟道2.0”巨模型的另⼀张标签。
⼤规模预训练模型的参数规模,通常远超传统的专⽤AI模型,在算⼒资源、训练时间等⽅面消耗巨⼤。
为了提升⼤规模预训练模型的产业普适性和易用性,悟道团队搭建高效预训练框架,实现了全链路的原创突破或迭代优化,预训练效率⼤幅提升,并且全部开源。

面向预训练模型的全链路高效训练框架CPM-2
(1)⾼效编码:研发了最高效、最抗噪的中⽂预训练语⾔模型编码,解决⽣僻字等问题;
(2)⾼效模型:构建了世界首个纯非欧空间模型,只需一半的参数量,即可达到近似欧式模型的效果;
(3)⾼效训练:世界首创⼤规模预训练模型融合框架,形成⾼效训练新模式,训练时间缩短27.3%,速度提升37.5%;
(4)⾼效微调:世界首创多类别Prompt微调,只需训练0.001%参数,即可实现下游任务适配;
(5)高效推理:世界首创低资源⼤模型推理系统,单机单卡GPU可进⾏千亿规模的模型推理。
悟道·文源还包含世界最大中文自然语言能力评测数据集,这是目前最全面系统的中文自然语言能力评测基准,能综合反映模型的语言能力。
智源指数
此外,智源研究院打造了全球最⼤的中⽂语料库WuDaoCorpora,扩展了多模态和对话两⼤全新元素,再次升级创造3项全球最⼤:最⼤中⽂文本数据集、多模态数据集、中⽂对话数据集。
除了规模⼤,该语料库仍延续了标签全、隐私保护好的优势特征。WuDaoCorpora2.0也将进行部分开放,为产业与研究进⾏数据⽀持。
目前,智源研究院计划免费开放200G悟道文本数据,研究人员可登录如下链接申请下载:
https://data.baai.ac.cn/data-set
四、已合作21家企业,“悟道”生态圈扩张中
智源研究院理事长张宏江认为,⼤模型将成为⼀个AI未来平台的起点,成为类似“电⽹”的基础建设,为社会源源不断供应智⼒源。

智源研究院理事长张宏江演讲
张宏江说,“悟道2.0”智能模型系统将构建“大模型、大平台、大生态”。
一是以“大规模”“高精度”“高效率”为发展目标,持续研发大模型;二是围绕大模型研发,构建大规模算力平台,支撑信息、生命、物理领域的大模型研发;三是通过示范应用搭建、API开放、开源社区等,构建大模型生态。
悟道大模型已在产业智能应⽤⽅面全⾯开花。
例如,智源研究院与新华社战略合作,将悟道大模型应⽤于新闻智能化转型,实现了新闻领域0到1的突破。
“悟道”能处理新闻下游任务,如新闻内容处理、图⽂生成、传播优化等,它还具备接近人类的图⽂创意能力,可以作诗、问答或进行创意写作。
此外,中国首位原创虚拟学生“华智冰”也现身智源大会开幕式。这个AI学生拜智源副院长、清华⼤学教授唐杰为师,今日进入清华实验室学习。
“她”具备持续学习新知识和回答复杂推理问题的能力,将逐渐学会写诗、作画、唱歌、编程等各种内容创作技能。
AI学生“华智冰”演示视频:背景音乐、面容、诗词、绘画作品,均基于“悟道2.0”大模型和小冰框架的AI内容生成技术
“华智冰”由智源研究院、智谱AI与小冰公司联合培养,基于智源悟道2.0超大模型、小冰AI完备框架、智谱AI数据与知识双轮驱动的AI框架而实现。研究人员们期望,“华智冰”在知识水平、情商等方面都会不断成长。
“悟道”⼤模型现已与美团、⼩米、快⼿、搜狗、360、寒武纪、好未来、新华社等21家产业生态合作企业进行战略合作签约,涵盖⾏业应⽤企业、IT⻰头企业、中⼩创新企业等。

悟道生态战略合作伙伴
同时,智源发起组建“悟道”⼤模型技术创新⽣态联盟的倡议,吸引更多企业加入,将以联盟为枢纽,以企业需求为导向,推动模型研发,共同开发基于“悟道”⼤模型的智能应用,从而促进产业集聚。
围绕“悟道”⼤模型产业生态建设,后续,智源研究院将⾯向个⼈开发者、中小创新企业、行业应⽤企业、IT领军企业等不同主体,分别提供模型开源、API调⽤、“专业版”⼤模型开发、大模型开发许可授权等多种形态的模型能⼒服务,赋能AI技术开发。
同时,智源研究院拟通过成⽴创业投资基⾦、举办“悟道之巅”模型应⽤创新大赛等⽅式,不断发掘和培育基于超⼤规模智能模型的创新企业,推动AI产业可持续发展。
五、智源最新进展:已遴选94位智源学者,建设8个智源创新中心
除了发布悟道2.0外,在智源大会开幕式上,智源研究院院长、北京大学教授黄铁军还分享了智源研究院的最新进展。
1、持续实施智源学者计划,引进培养优秀科学家
截至目前,智源学者计划已遴选智源学者94人,分别来自北大、清华、中科院等高校院所与旷视、京东等优势企业。
他们的研究覆盖人工智能的数理基础、人工智能的认知神经基础、机器学习、自然语言处理、智能信息检索与挖掘、智能系统架构与芯片等重大研究方向。
2、建设“超大规模人工智能模型训练平台”
智源研究院加紧部署通用智能发展,推动建设“超大规模人工智能模型训练平台”,研制“信息、生命、物质”领域超大规模智能模型,以及搭建模型训练及运行所需的大规模算力资源及软件环境。

智源创新的中心任务:三个智能模型+一套智算体系
其中,算力资源部分将建成体系架构先进、高速互联互通、可扩展高效并行的AI超级计算平台,同时,通过搭建AI软硬件测试验证平台,遴选百度昆仑、华为昇腾、寒武纪思元等高性能国产AI芯片及软件参与平台建设,为AI前沿技术提供试验验证环境。
3、建立智源创新中心,推动原创成果转化落地
迄今智源研究院已经建设8个智源创新中心,覆盖疾病脑电、智能信息处理、认知知识图谱、安全人工智能等方向,通过开放智源的生态资源,支持关键核心技术攻关,推动AI原始重大创新和关键技术落地和深度应用。
在本届智源大会上,智源研究院将于6月3日发布源创计划,提供两类服务:一类是技术驱动,即扶持科学家创业;另一类是需求拉动,给缺乏AI技术、想转向智能化的企业做技术对接。

智源源创计划
4、开放高质量数据集,建设联合实验室
智源数据开放研究中心重点建设智能医疗等行业的高质量AI数据集,面向业界提供数据共享服务,推出智能平台,并组织相关数据竞赛。
悟道数据团队还构建了全球最大中文语料数据库WuDaoCorpora,这次WuDaoCorpora2.0扩展了多模态和对话两大全新元素,再次升级创造3项全球最大:最大中⽂文本数据集(3TB)、多模态数据集(90TB)与中⽂对话数据集(181G)。

另外,智源研究院与旷视、京东分别建设并开放了全球最大的物体检测数据集Objects365、全球最大多轮对话文本数据集。智源研究院还分别联合旷视、京东、予果生物等企业共建实验室,推动场景开放,实施协同创新。
5、建设智源社区,举办北京智源大会
社区方面,智源研究院推动智源社区建设,着力构建AI学者社交网络,建立活跃的AI学术和技术创新生态,培养下一代问题的发现者、解决者。
目前,智源社区已汇聚6万名AI学者和技术人员,未来,智源社区将紧密联系3000名以上的顶尖AI学者,辐射10万以上AI科研和技术人员。
6、参与并引领国际AI治理,促进AI可持续发展
2019年5月,智源研究院成立人工智能伦理与可持续发展研究中心,并同北大、清华、中科院计算所等单位联合发布了我国第一个人工智能发展与治理准则——《人工智能北京共识》。
为推动北京共识落地,智源研究院将在2021年9月发布我国首个针对儿童的人工智能发展原则《面向儿童的人工智能北京共识》,并在建设我国首个“人工智能治理公共服务平台”,针对AI技术在研发及应用过程中潜在的伦理问题提供检测服务。
它还发起了成立国际组织“面向可持续发展的人工智能协作网络”,剑桥大学、新加坡管理大学、联合国机器人与人工智能中心等机构已加入。
结语:开启国内超大规模模型时代
在智源研究团队眼中,未来,⼤模型将成为类似“电⽹”的新平台,将AI的“智力”如同电力般,源源不断、⼜高效普惠地输送进各⾏各业。
智源“悟道”巨模型,正是这⼀趋势的先⾏者。
这一万亿参数模型的里程碑式突破,与智源攻关团队深厚的算法根基、数据积累和算力汇聚能力都密不可分。
自2018年底成立以来,智源研究院持续汇集国内顶尖AI人才,推进AI领域最基础问题和最关键难题的研究,并陆续取得许多国际领先的新成果。
接下来,“悟道”不止是要做“中国第⼀”,而且要持续瞄向世界顶尖水平,让机器全方面接近⼈的思考,迈向通⽤⼈工智能。
也就是说,以后你在知乎看到的“谢邀”答主,你在展览上看到的设计大师,说不定就是AI了。
今日推出的“悟道”,仅是智源研究院的重大研究进展之一。在开幕式后,2021北京智源大会将于6月1日至3日期间,围绕各种国际AI前沿和产业热点召开29场专题论坛,分享最新研究成果。

除了在今天上午发表演讲的图灵奖得主、加拿大蒙特利尔大学教授Yoshua Bengio之外,图灵奖得主、计算机体系结构宗师David Patterson,2017年欧洲大脑奖得主、世界著名神经科学家Peter Dayan,加州大学伯克利分校人工智能统计中心创始人Stuart Russell,自动驾驶之父Sebastian Thrun,计算可持续性领域开创者Carla Gomes,国内AI经典西瓜书《机器学习》作者、南京大学教授周志华等国内外200余位尖端AI专家,均将在接下来的三天内分享前沿思想。
后续,智东西将发来更多北京智源大会的报道,包括与学术领袖的采访交流,敬请期待。
