字幕组双语原文:Google Translate 的新改进
英语原文:Recent Advances in Google Translate
翻译:雷锋字幕组(明明知道)
机器学习(ML)的进步推动了自动翻译的进步,包括 2016 年在翻译中引入的 GNMT 神经翻译模型,它极大地提高了 100 多种语言的翻译质量。然而,除了最具体的翻译任务之外,最先进的翻译系统在所有方面都远远落后于人类的表现。虽然研究界已经开发出了一些技术,成功地应用于高资源语言,如西班牙语和德语,这些语言有大量的训练数据,但在低资源语言,如约鲁巴语或马拉雅拉姆语,性能仍有待提高。在受控的研究环境中,许多技术已经证明了对低资源语言的显著改善(例如 WMT 评估运动),然而这些在较小的、公开的数据集上的结果可能不容易转换到大型的、网络爬得数据集。
在本文中,我们将通过综述和扩展各种最新进展,分享一些我们在支持语言的翻译质量方面所取得的进展,特别是那些资源较少的语言,并演示如何将它们大规模应用于嘈杂的、Web 挖掘的数据。这些技术包括模型架构和训练的改进,数据集中噪音的改进处理,通过 M4 建模增加多语言迁移学习,以及单语数据的使用。BLEU 分数在所有 100 多种语言中平均为增加 5 分,翻译质量提高如下图所示。
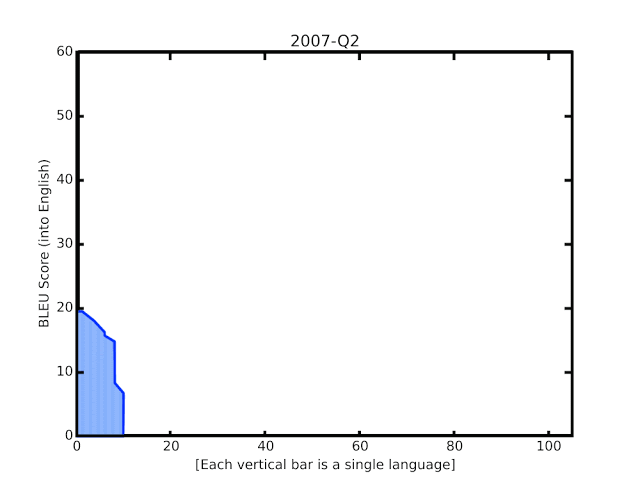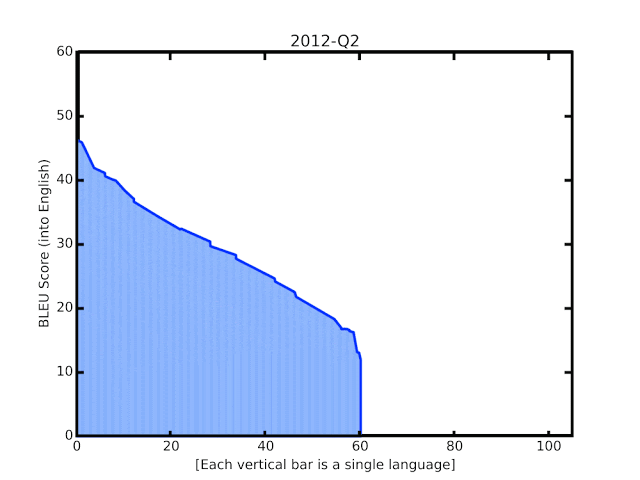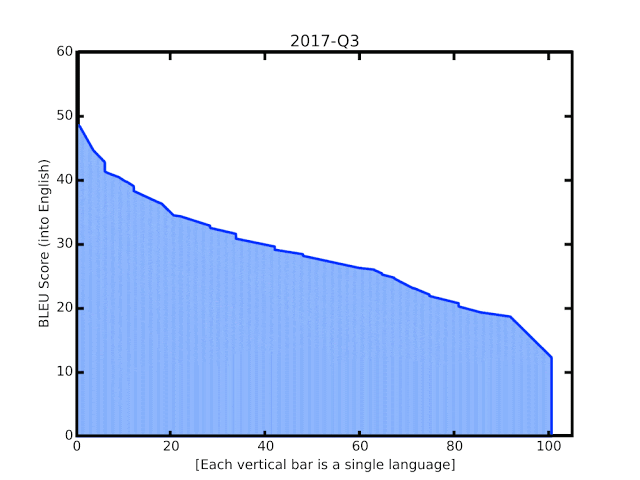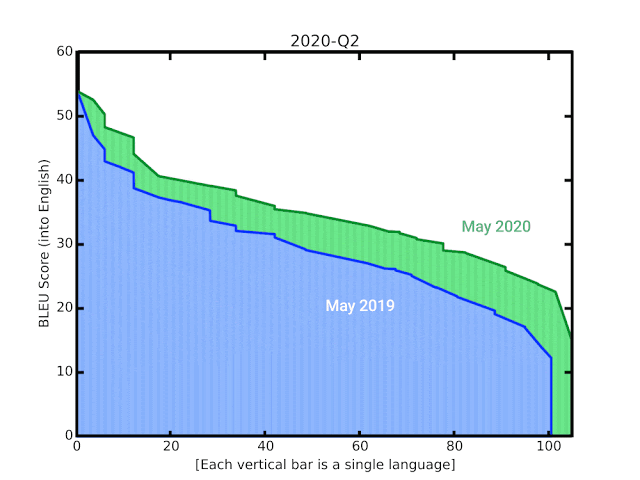
谷歌的 BLEU 评分自 2006 年成立后不久就开始翻译模型。最后的动画效果显示自去年实施新技术以来得到了提升。
对高资源和低资源语言的改进
混合模型架构:四年前我们引入了基于 RNN 的 GNMT 模型,它带来了巨大的质量改进,并使翻译覆盖了更多的语言。随着我们对模型性能的不同方面的解耦工作的进行,我们替换了原来的 GNMT 系统,用一个 transformer 编码器和一个 RNN 解码器来训练模型,用 Lingvo(一个 TensorFlow 框架)实现。Transformer 模型已经被证明在机器翻译方面比 RNN 模型更有效,但我们的工作表明,这些质量的提高大部分来自变压器编码器,而 Transformer 译码器并不比 RNN 译码器明显好。由于 RNN 解码器在推理时间上要快得多,我们在将其与 transformer 编码器耦合之前进行了各种优化。由此产生的混合模型质量更高,在训练中更稳定,表现出更低的潜伏期。
网络爬取:神经机器翻译(NMT)模型使用翻译句子和文档的示例进行训练,这些示例通常是从公共网络收集的。与基于短语的机器翻译相比, NMT 对数据质量更加敏感。因此,我们用一个新的数据挖掘器取代了以前的数据收集系统,它更注重精确率而不是召回率,它允许从公共网络收集更高质量的训练数据。此外,我们将 Web 爬虫从基于字典的模型转换为基于 14 个大型语言对的嵌入模型,这使得收集到的句子数量平均增加了 29%,而精度没有损失。
建模数据噪声:具有显著噪声的数据不仅冗余,而且会降低在其上训练的模型的质量。为了解决数据噪声问题,我们利用去噪 NMT 训练的结果,使用在有噪声数据上训练的初步模型和在干净数据上进行微调的模型,为每个训练示例分配一个分数。然后我们把培训当作一个课程学习问题——模型开始对所有数据进行培训,然后逐渐对更小、更清晰的子集进行培训。
这些进步尤其有利于低资源语言
反向翻译:在最先进的机器翻译系统中广泛采用,反向翻译对于并行数据稀缺的低资源语言特别有用。这种技术将并行训练数据(一种语言的每句话都与它的翻译配对)与合成并行数据(一种语言的句子由人编写,但它们的翻译是由神经翻译模型生成的)相加。通过将反向翻译合并到谷歌翻译中,我们可以利用网络上更丰富的低资源语言的单语文本数据来训练我们的模型。这对于提高模型输出的流畅性尤其有帮助,而这正是低资源转换模型表现不佳的领域。
M4 建模:M4 是一种对低资源语言特别有帮助的技术,它使用一个单一的大型模型在所有语言和英语之间进行转换。这允许大规模的迁移学习。分享一个例子,低资源语言像意第绪语能通过联合其他相关日耳曼语言(如德国、荷兰、丹麦等)进行训练,与近一百个其他的、不可能共享一个已知连接的语言,获得有用的信号模型。
评判翻译质量
对于机器翻译系统的自动质量评估,一个流行的衡量标准是 BLEU 评分,它是基于系统的翻译和人们生成的参考翻译之间的相似性。通过这些最新的更新,我们看到 BLEU 平均比以前的 GNMT 模型提高了 5 分,其中 50 种资源最低的语言平均提高了 7 分。这一进步与四年前从基于短语的翻译过渡到 NMT 时观察到的增益相当。
尽管 BLEU 分数是一个众所周知的近似度量,但众所周知,对于已经高质量的系统来说,它有各种各样的缺陷。例如,有几部作品演示了在源语言或目标语言上的翻译语效应如何影响 BLEU 分数,在这种现象中,翻译的文本可能听起来很别扭,因为其中包含源语言的属性(如词序)。基于这个原因,我们对所有的新模型进行了并排的评估,结果证实了在蓝带的效果。
除了总体质量的提高之外,新模型对机器翻译幻觉的鲁棒性也有所增强。机器翻译幻觉是指当输入无意义的信息时,模型会产生奇怪的“翻译”。对于那些在少量数据上进行训练的模型来说,这是一个常见的问题,并且会影响许多低资源语言。例如,当考虑到泰卢固语字符的字符串“షషషషషషషషషషషషషషష”,旧的模式产生了荒谬的输出“深圳肖深圳国际机场(SSH)”,似乎试图理解的声音,而新模型正确学会直译为“Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh Sh”。
结论
尽管对于机器来说,这些都是令人印象深刻的进步,但我们必须记住,特别是对于资源较少的语言,自动翻译的质量远远不够完美。这些模型仍然是典型的机器翻译错误的牺牲品,包括在特定类型的主题(“领域”)上表现不佳,合并一种语言的不同方言,产生过多的字面翻译,以及在非正式语言和口语上表现不佳。
尽管如此,通过这次更新,我们很自豪——提供了相对连贯的自动翻译,包括支持的 108 种语言中资源最少的语言。我们感谢学术界和工业界的机器翻译研究人员所做的研究。
致谢
这一成果基于以下这些人的贡献:Tao Yu, Ali Dabirmoghaddam, Klaus Macherey, Pidong Wang, Ye Tian, Jeff Klingner, Jumpei Takeuchi, Yuichiro Sawai, Hideto Kazawa, Apu Shah, Manisha Jain, Keith Stevens, Fangxiaoyu Feng, Chao Tian, John Richardson, Rajat Tibrewal, Orhan Firat, Mia Chen, Ankur Bapna, Naveen Arivazhagan, Dmitry Lepikhin, Wei Wang, Wolfgang Macherey, Katrin Tomanek, Qin Gao, Mengmeng Niu, 和 Macduff Hughes.
雷锋字幕组是由AI爱好者组成的志愿者翻译团队;团队成员有大数据专家、算法工程师、图像处理工程师、产品经理、产品运营、IT咨询人、在校师生;志愿者们来自IBM、AVL、Adobe、阿里、百度等知名企业,北大、清华、港大、中科院、南卡罗莱纳大学、早稻田大学等海内外高校研究所。
了解字幕组请联系微信:tlacttlact
转载请联系字幕组微信并注明出处:雷锋字幕组
雷锋网雷锋网