
深度强化学习在自主解决复杂、高维问题方面的前景,引起了机器人、游戏和自动驾驶汽车等领域的极大兴趣。但是,要想有效地进行强化学习策略的训练,需要对大量的机器人状态和行为进行研究。这其中存在一定的安全风险,比如,在训练一个有腿机器人时,由于这类机器人自身不稳定,机器人在学习时很容易发生跌倒,这可能会造成机器人的损害。
通过在计算机模拟中学习控制策略,然后将其部署在现实世界中,可以在一定程度上降低机器人发生损害的风险。但是,该方法往往要求解决模拟到现实的差距,即在模拟中训练的策略由于各种原因不能随时部署在现实世界中,比如部署中的传感器噪音或模拟器在训练中不够真实。解决这个问题的另一种方法,就是在现实世界中直接学习或微调控制策略。当然,最主要的挑战还是如何在学习过程中确保安全。
在《腿部运动的安全强化学习《Safe Reinforcement Learning for Legged Locomotion》的论文中,我们提出了一个安全的强化学习框架,用于学习腿部运动,同时满足训练期间的安全约束。
我们的目标是让机器人在现实世界中自主学习动作技巧,并且在学习过程中不会跌倒。我们的学习架构使用了一种双重策略的强化学习框架:一种将机器人从近乎不安全的状态中恢复过来的“安全恢复策略”,以及一种为执行所需控制任务而优化的“学习者策略”。安全学习框架在安全恢复策略和学习者策略之间进行切换,使机器人能够安全地获得新的、敏捷的动作能力。
双重策略的强化学习框架
我们的目标是确保在整个学习过程中,无论使用何种学习者策略,机器人都不会跌倒。
与儿童学骑车一样,我们的做法是,在使用“训练轮”的同时,教会智能体一种策略,即安全恢复策略。我们首先定义了一组状态,我们称之为“安全触发集”,在这些状态下,机器人在接近于违反安全约束的情况下,但能通过安全恢复策略来挽救。
例如,安全触发集可以被定义为:机器人的高度低于某个阈值,并且滚动、俯仰、偏航角度过大的一组状态,这是一个跌倒的迹象。当学习者策略的结果是机器人处于安全触发集内(即有可能跌倒的地方),我们就切换到安全恢复策略,驱动机器人回到安全状态。
我们通过利用机器人的近似动力学模型来预测未来的机器人轨迹,从而确定何时切换回学习者策略。例如,基于机器人腿部的位置和基于滚动、俯仰和偏航传感器的机器人的当前角度,它在未来是否有可能跌倒?如果所预测的未来状态都是安全的,我们就把控制权交还给学习者策略,否则,我们就继续使用安全恢复策略。
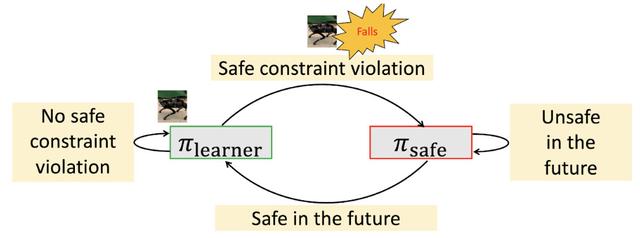
上图是我们所提方法的状态图
- 如果学习者策略违反了安全约束,我们就切换到安全恢复策略。
- 如果切换到安全恢复策略后,短期内无法保证学习者策略的安全时,我们将继续使用安全恢复策略。这样,机器人就能更好地进行探索,而又能保证安全。
这种方法确保了复杂系统的安全,而不需要借助于不透明的神经网络,这些神经网络可能对应用中的分布改变很敏感。此外,学习者策略能够探索接近安全违规的状态,这对于学习一个稳健的策略很有用。
由于我们使用“近似”动力学来预测未来的运动轨迹,所以我们也在探讨,在机器人的动力学方面,采用更精确的模型时,会有多大的安全性。我们对这个问题进行了理论分析强化学习 leggedlocomotion/),显示出我们的方法与对系统动力学有充分了解的方法相比,可以实现最小的安全性能损失。
腿部运动任务
为验证该算法的有效性,我们考虑学习三种不同的腿部动作能力:
- 高效步态:机器人学习如何以低能耗的方式行走,并因消耗较少的能量而得到奖励。
- 猫步:机器人学习一种猫步的步态,在这种步态中,左、右两只脚相互靠近。这很有挑战性,因为通过缩小支撑多边形,机器人会变得不太稳定。
- 两腿平衡:机器人学习两腿平衡策略,在这个策略中,右前脚和左后脚处于站立状态,另外两只脚被抬起。如果没有精确的平衡控制,由于接触多边形会“退化”成一条线段,所以机器人很可能会跌倒。

本文所讨论的运动任务。上图:高效步态。中间:猫步。下图:两腿平衡。
实施细节
我们使用一个分层策略框架,将强化学习和传统控制方法相结合,用于学习者和安全恢复策略。这个框架包括一个高级的强化学习策略,它产生步态参数(例如,踏步频率)和脚的位置,并将其与一个称为模型预测控制(model predictive control,MPC)的低级过程控制器配对,该控制器接收这些参数并计算出机器人中每个电机的理想扭矩。
由于我们不直接控制电机的角度,这种方法提供了更稳定的操作,由于较小的行动空间而简化了策略训练,并产生了更强大的策略。强化学习策略网络的输入包括先前的步态参数、机器人的高度、基座方向、线性、角速度和反馈,这些信息可以显示机器人是否已经接近设定的安全触发器。对于每个任务,我们都会采用同样的设定。
我们训练一个安全恢复策略,对尽快达到稳定状态给予奖励。此外,在设计安全触发集时,我们也从可捕捉性理论中得到了灵感。尤其是,最初的安全触发器集被定义为,确保机器人的脚不会踩在能够利用安全恢复策略进行安全恢复的位置之外。我们使用了一个随机策略,在一个真实的机器人上对安全触发集进行了微调,以防止机器人跌倒。
现实世界的实验结果
我们报告了现实世界的实验结果,显示了奖励学习曲线和高效步态、猫步和两腿平衡任务中安全恢复策略激活的百分比。为了确保机器人能够学会安全,我们在触发安全恢复策略时增加了一个惩罚。这里,所有的策略都是从头开始训练的,除了两腿平衡任务,由于需要更多的训练步骤,所以在模拟中进行了预训练。
总的来说,我们发现,在这些任务中,奖励增加了,而当策略更新时,安全恢复策略的适用百分比也会下降。比如,在高效步态任务中,安全恢复策略的使用比例从 20% 下降到接近 0%。对于两腿平衡任务,百分比从接近 82.5% 下降到 67.5%,这表明两腿平衡比前两个任务要难得多。
尽管如此,该策略确实提高了奖励。研究结果显示,在不触发安全恢复策略的情况下,学习者可以可以逐步学习任务。另外,这说明在不影响性能的情况下,可以设计一套安全触发器集和安全恢复策略。
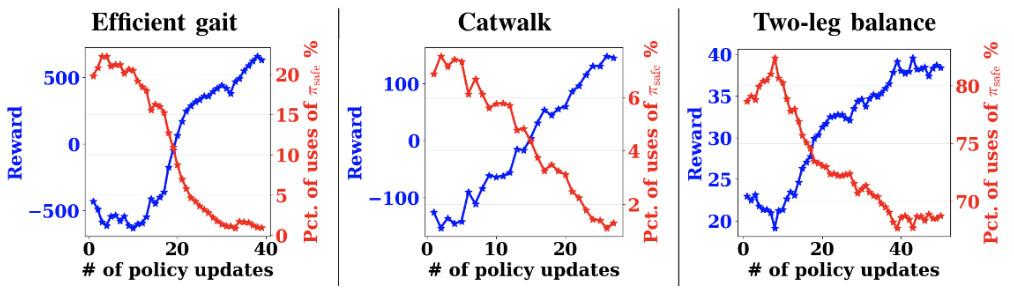
在现实世界中使用我们的安全强化学习算法的奖励学习曲线(蓝色)和安全恢复策略激活的百分比(红色)。
此外,下面的动图显示了两腿平衡任务的学习过程,包括学习者策略和安全恢复策略之间的相互作用,以及当一个情节结束时重置到初始位置。
我们可以看到,当机器人跌倒时,它会试着抬起腿并伸出去(左前腿和右后腿),把自己拉起来,从而形成一个支撑多变形。在学习一段时间后,机器人会自动走回重置的位置。这使得我们自主、安全地进行无人监督的策略训练。

早期训练阶段

后期训练阶段

没有安全的恢复策略
最后,我们将学习到的一些策略进行演示。首先,在猫步任务中,两边腿的距离为 0.09 米,比额定距离小 40.9%。第二,在两腿平衡任务中,机器人可以通过两腿跳动来保持平衡,而从模拟中预先训练的策略只跳了一次。

最终,机器人学会了两腿平衡。
结语
我们提出了一种安全的强化学习框架,并展示了在学过程中,不会跌倒或手动复位的情况下,如何训练机器人的策略进行高效步态和猫步任务。这种方法甚至能够在只有四次跌倒的情况下训练两腿平衡任务。只有当需要时,才会触发安全恢复策略,使得机器人可以更好地进行环境的探索。
我们的研究结果显示,在现实世界中,能够自主、安全地掌握腿部动作的技巧是有可能的,这将为我们提供一个新的机遇,其中包括离线收集机器人学习的数据集。
没有任何模型是没有限制的。我们目前在理论分析中,忽略了来自环境和非线性动态的模型不确定性。把这些纳入其中,可以使我们的方法更加通用。另外,当前,切换标准中的某些超参数也以启发式方法进行调整。若能根据学习的进度,自动地决定切换的时间,则更会有效。如果把这种安全的强化学习框架扩展到其他的机器人应用,如机器人操纵,将会很有意思。
最后,在考虑到安全恢复策略时,设计一个适当的奖励,将会影响学习性能。我们使用了一种基于惩罚的方法,在这些实验中获得了合理的结果,但我们计划在未来的工作中对此进行研究,以进一步提高性能。
原文链接:
https://ai.googleblog.com/2022/05/learning-locomotion-skills-safely-in.html
了解更多软件开发与相关领域知识,点击访问 InfoQ 官网:https://www.infoq.cn/,获取更多精彩内容!