
只需输入作者名,电脑就能帮你生成一篇“SCI级别”的计算机论文。
摘要、背景介绍、实验结果、图表、讨论以及结论等都一应俱全。
世上就是有这等美事。
只要你想,一口气就能搞个几百篇计算机论文。
尽管SCIgen只是一个网页程序,但它产出的论文格式可能比一些本科论文还要规范。

这是本人用SCIgen自动生成的论文,SCIgen官方网站为https://pdos.csail.MIT.edu/archive/scigen/感兴趣的可以自己一试
不过也别高兴得太早,到目前为止AI还无法取代人类完成科研任务。
别看这些生成的论文有模有样,但根本没有地球人能看得懂。
不是因为太高深,内容纯属是“一本正经地胡说八道”。
但这并不要紧,因为在学术界总是会有人上当。
将这些计算机论文,投稿到一些国际学术期刊还会被录用,极具讽刺意味。

SCIgen界面
学术出版界也是个江湖,同样鱼龙混杂。
并不是所有人,都奔着证明自己或是发现真正有价值的东西而来。
而SCIgen这个程序的诞生,就是为了戏耍学术界的那些“野鸡期刊”。
这些只以盈利为目的的野鸡期刊也叫掠夺性期刊(Predatory journals
),学术质量与信誉都很低。
他们的日常就是疯狂地给科研人员发送垃圾邮件,以“征集论文”之名吸引那些没有发表经验的学者上当。

一般来说在论文发表前,学术刊物主编会邀请专业领域内有一定造诣的同行学者,评议论文的质量。
这也叫同行评议,刊物会按评议结果决定是否发表。
但掠夺性期刊,只要钱到位他们都能安排论文的发表,连审都不用审。
因为日常不堪骚扰,麻省理工学院(MIT)计算机科学与人工智能实验的几个学生就看不过去了。
2005年,Dan Aguayo、Max Krohn和Jeremy Stribling三人,决定向这种”水”得不行的期刊和会议宣战。

从左到右分别为Dan Aguayo、Max Krohn和Jeremy Stribling
那时已临近学期末,但这MIT三剑客还是花了一两星期去开发这个小程序。
SCIgen的原理很简单,有些类似于填词游戏。
学术论文的格式是非常相似的,它本身就充满了专业词汇和固定的句式。
而SCIgen则能够从固定的词库中,随机抽取出这类计算机领域内的专业术语,以符合语法的方式生成文本。
再加上一些漂亮的图表和详细的参考文献等,就能骗过不少外行。
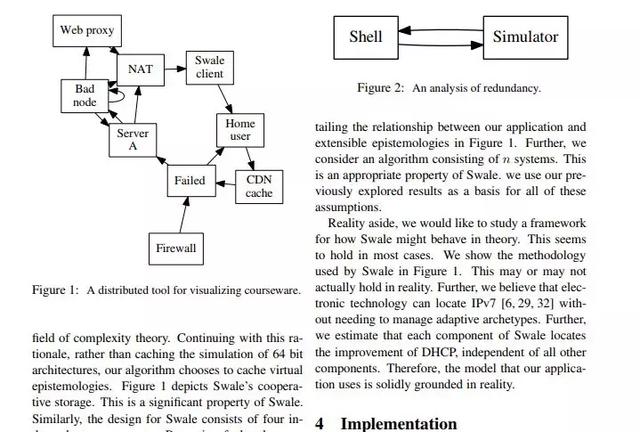
SCIgen生成的论文中带有的图表
但这个软件真没多厉害,内行人一看就知道全文是在“胡说八道”。
要怪,就怪一些期刊和会议灌水得太过分了。
不出所料,他们第一篇自动生成的论文就攻破了WMSCI(World Multiconference on Systemics, Cybernetics and Informatics)会议的防线。
这篇论文名为《Rooter:处理接入点与冗余的典型合一方法》,看似高大上其实内容根本不知所云。
而WMSCI会议,不但接受了这篇假论文,还邀请作者出席会议作报告。

这下可高兴坏了MIT三剑客。
毕竟在这之前,他们就听说WMSCI会议以接受水货著称,但没真想到他们居然这么水。
于是,他们便把SCIgen攻陷WMSCI的事情经过发到网上。
一波嘲讽下来,这在科研圈立马引起了广泛的关注。
毕竟大家早就看不惯这些掠夺性期刊和会议。

这下WMSCI会议是颜面扫地,立马撤回了对他们团队的邀请。
不过,失去报告资格,这三剑客反倒来了兴致。
利用在网络上众筹来的2500美金,他们决定将恶作剧升级,搞一波大的。
这三人,长途跋涉地在同一天赶往了会议所在的佛罗里达州奥兰多市。
就在大会举办的同一地点,他们租了一块场地,用“假身份”开了一场属于自己的“分会场”。

“假会议”现场,该有的都有
想要伪装一场学术会议并不难,和论文灌水一样只要有钱就够了。
而报告内容用SCIgen就能无限生成,这种垃圾想要多少就有多少。
除此之外,他们还置办了一批假的宣传海报、假名片、假胡子和假发等。
反正,这场学术会议的一切都是假的。
但这并不妨碍有人上当,当时来听他们装模作样演讲的人还不少。
如果不明真相,或许这些人到现在都仍以为自己是在听WMSCI的报告。

演讲现场,图中为戴着假发的Jeremy Stribling
但这场闹剧,并没有随着这场假学术会议的结束而收场。
刚开始,只是IEEE撤销了对WMSCI会议的资助。
到后来,越来越多人开始使用SCIgen产出的“钓鱼文”在其他学术期刊“试水”。
现阶段,这三位SCIgen元老已步入职场,深藏功与名。
而他们留下的这款软件,则将学术界搅得天翻地覆。

例如,德国的学生利用这款神器,就攻下了2008年和2009年在中国武汉举办的两个IEEE国际会议。
当时,Schlangemann教授就被当成知名学者,还被邀请作为会议的主持人出席。
但Schlangemann教授并非真有其人,他只是一个由这位学生创造的虚拟角色。
而这个名字,则源于一部名为Der Schlangemann的德国电影。
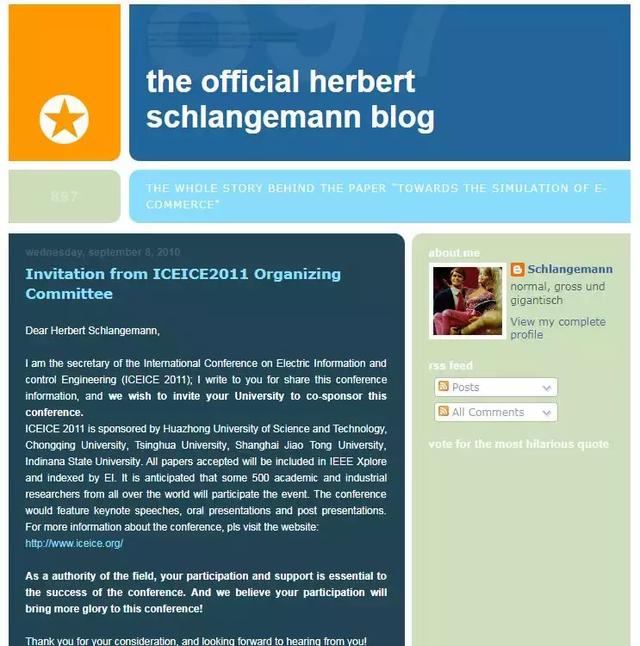
Schlangemann教授还有虚拟的个人网站,感兴趣可以自行搜索Der Schlangemann的形象,比想象中还要讽刺
现在SCIgen的访问量依然惊人。每年的浏览量仍超过60万次,无数钓鱼文在源源不断地产出。
这导致了这个页面,隔几个月就要崩溃一回。
2013年,法国格勒诺布尔大学的研究员Cyril Labbé就透露了一个令人不安的事实。
他在IEEE和Springer出版公司旗下的期刊中,就发现了超过120篇SCIgen生成的诈文。
对于自己是否已彻底排查出所有乱入的伪论文,Labbé自己心里也没底。
因为他本人也无法从有限的订阅源内下载所有的论文。
这也是学术出版商常常遭到诟病的一点。
想在期刊上发论文需要收取高昂的版面费,但想在上面下载论文则又要付另外一笔费用。
就算是作者本人在学术期刊上发表的论文,想要下载都不能例外,一律收费。

而除了期刊的审核不严格,Labbé还揭示了另一个漏洞。
那就是,利用SCIgen这类垃圾论文软件,竟可以给自己狂刷h指数(H index)。
一名科研人员的h指数,是指他至少有h篇论文被引用了至少h次。
这是评价个人学术成就的一个新方法。
例如,某人的h指数是20,这表示他已发表的论文中,每篇被引用了至少20次的论文总共有20篇。
但所谓的H指数,在SCIgen的捣乱下就无法起效了。

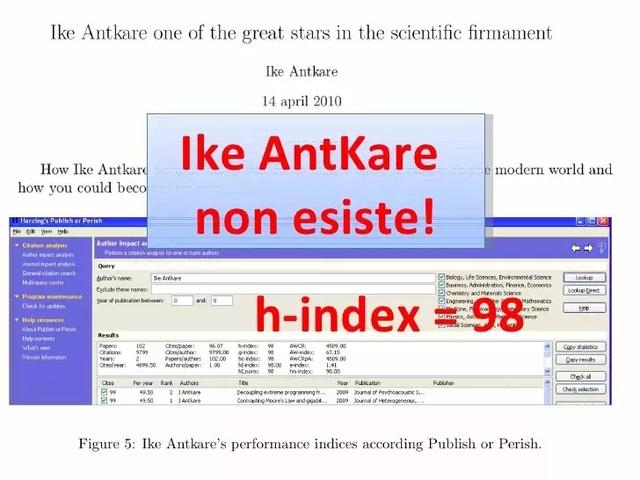
当时,Labbé就以“IKE ANTKARE”作为作者名(注意,IKE ANTKARE这人并不存在),用SCIgen生成了102篇垃圾论文。
这让IKE ANTKARE在谷歌学术中的h指数,一下子飙升到了94。
他还一度挤进了计算机科学领域科学家中h指数排名的前六。
当然,为了让h指数变高,他也用了一点小技巧。
这100篇假论文中,每篇都会对所有作者名为IKE ANTKARE的假论文进行引用。
而为了让谷歌学术能够对这100篇论文进行索引,Labbé还在参考文献中加入了唯一一篇真实的,已被谷歌学术索引的论文。
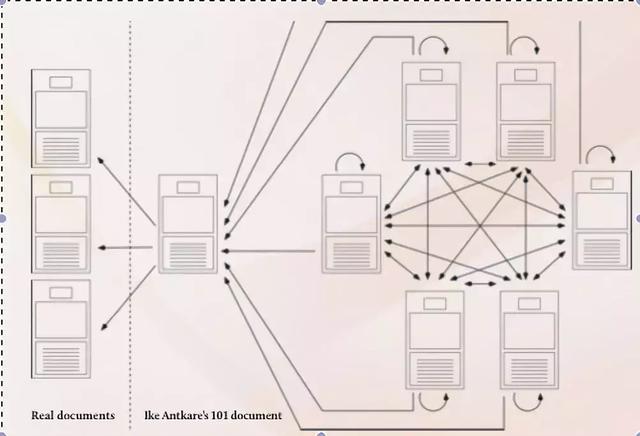
“我自己引用自己”,就这样IKE ANTKARE凭一己之力就成了学术界冉冉升起的新星。
这一虚拟人物的h指数,甚至比爱因斯坦还要高。
当然,IKE ANTKARE这颗学术新星陨落得也很快。
因为Labbé已经将自己的一系列骚操作写成论文,对世人公开了IKE ANTKARE的虚拟身份。
随后谷歌学术,就对IKE ANTKARE进行了封杀并删除了他的论文。

Cyril Labbé本人
因为一些知名学术期刊,会对这些计算机生成的诈文照单全收。
那么,我们就有理由相信一些作者会把SCIgen当作赚钱的工具。
于是,为了揪出这些混入科学期刊的诈文,Labbé就与Springer合作特意开发了一款针对SCIgen的软件——SciDetect。
这款开源软件,能够自动检测出哪些是由SCIgen生成的假论文。

但在这之后,SCIgen的创始人之一Stribling是这样评价此事的。
“他们开发了一个新程序,而不是制定更好的政策让所有被接受的论文有更好的评审过程,这事本身就挺搞笑的”。
事实上,SciDetect的作用并不大,想要绕开这个程序的检测并不难。
Stribling表示,如果这是一场军备竞赛,他敢打赌再次骗过SciDetect只是时间的问题。

事实上,学术钓鱼从上个世纪就已经存在了。
早在1996年,量子物理学家艾伦·索卡尔(Alan Sokal)撰写的一篇科学诈文,就引起了一场“科学大战”。
他将一篇充满了常识性错误的论文,投稿至著名的文化研究杂志《社会文本》。
标题为《超越界限:走向量子引力的超形式的解释学》。
结果《社会文本》的五位主编,都没有发现这是一篇诈文,还一致通过将文章发表。
东窗事发,这立即触发了一场席卷全球的科学大论战,世界众多著名的媒体都参与其中。

艾伦·索卡尔
相比SCIgen,艾伦·索卡尔还是比较有诚意的。
尽管内容还是一本正经地胡说八道,但论文毕竟还是他自己亲手炮制的。
他将量子物理学中的术语、后现代主义领军人物的术语,还有他自己捏造词句糅合在了一起。
于是便得到了一篇毫无学术内涵,但又充满“后现代”风格的诈文。
而作为学术钓鱼的鼻祖,之后的学术钓鱼事件都被称为“索卡尔的平方”。
那么学术钓鱼,何时能消失?很简单,只有鱼儿不上钩,钓鱼就会自动失去意义。
*参考资料
Adam Conner-Simons.How three MIT students fooled the world of scientific journals.MIT News.2015
Jerrusalem.“三傻”大闹科研坞:我们怎么钓出了那些水货?.果壳网专访.2015
李慧翔.给我一篇假论文,我能骗倒半个地球.南方周末.2013
John Bohannon.Hoax-detecting software spots fake papers.Science.2015
CYRIL LABBÉ.One of the great stars in the scientific firmament. ISSI NEWSLETTER.201