
好好讲话的ONE读君 | didi
最近,你有上网冲浪吗,有get到一些京彩绝伦的笑点吗?
等一下,没有错别字,“京”是“吴京”的“京”。
吴京的微博有多好笑,没有从头翻到尾的人不会知道。微博上有博主稍微扒拉了一下,总结出了“和死鬼段奕宏打情骂俏合集”“那些年剩男的苦闷发言”“登山勇夺第一太兴奋不幸彻夜头痛合集”“和吕建民喝酒掰车筐合集”“和孙楠录歌始末”等等。

在“剩男的苦闷发言合集”中,吴京转发了一位鸡汤博主写的“白羊座的爱”,大概就是讲这个星座如何地长情,如何地踏实,如何地纯粹。兴许是被自己的一往情深打动了,他情绪激昂地讲了句:So TM true!!!
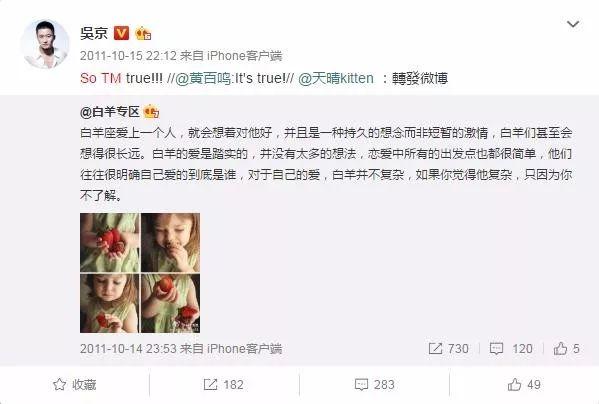
还有人(那个人就是我)翻出了他跟演员马丽的互动,开口也是“谁扶?谁不服?so tm what啊!”
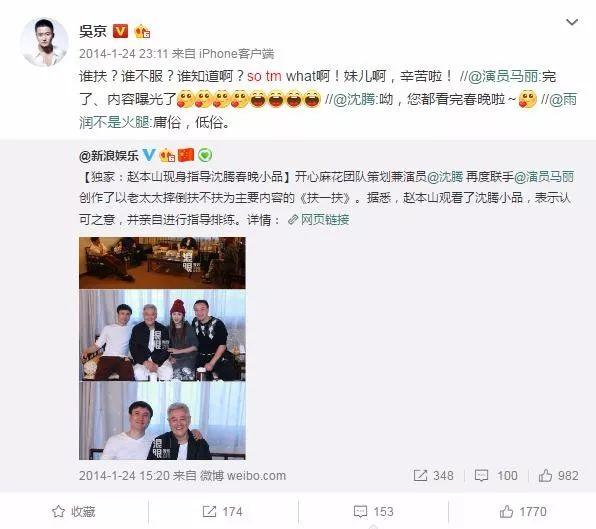
网友被逗乐了,觉得这种“英文+中文拼音”的说话方式简直不要太有趣,于是纷纷模仿京式英语造句:
——so tm true!
——笑tm死!
——So Tm 搞笑!
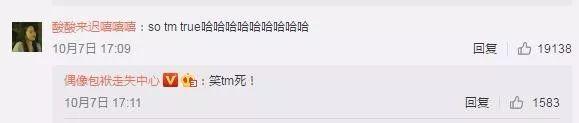
大家伙儿都笑晕了,真是so tm happy!
其实这种中文夹英文的造句,已成为一种很常见的说话方式,不知道你身边是否有人这样讲话:
——完蛋了,我明天有个Assignment要Due!
——Fiona,下午的会议室帮我Cancel一下!
——我很讨厌她,But她真的很努力。
更古早的句式还有:
——Hello啊,饭已经OK了,下来米西吧。
很多人不喜欢这种讲话方式,甚至对此深恶痛绝,觉得大家都是中国人,完全不使用英文很难吗?但当事人也会委屈,觉得自己只是说成习惯,当下脱口而出了,并没有其他意思。
So,为什么有些人讲话喜欢中文夹英文单词,这是出于什么心态?以及,这就是传说中的zhuangbility吗?
中文英文,看谁跑得更快
在中文里夹英文单词,其实是一种常见的语言现象,叫语码转换(Code-switching),是指一个人在一个对话中交替使用多于一种语言或其变体。
这种现象经常发生在多语言者的日常说话中,譬如回国不久的留学生、双语工作环境的白领、被英语四六级折磨的学生群体等。他们在沟通中,常常会面临使用哪种语码更得体的问题,即使嘴上没有表现出来,但大脑却经常在两种语码中跳跃和转换。
那么大脑是如何选择使用哪种语码的,母语or第二语言?
答案是,看速度。
语言的作用只是要表达人们大脑里的内容,当你说话时,其实是一种内在的翻译机制,把你自己的思想翻译成了一种具体的语码,说出来成言语,让对方听到和理解。不同的语言之间会有冲突。当你学习和使用了一门新的语言,那么势必会对你原来的语言系统产生影响,因为语言之间的冲突不可调和。
当你掌握了两种及以上的语言之后,就意味着你拥有了两种翻译方式,真正讲话时,哪一个翻译速度更快,先说出口的就是哪一种语言,因为这种语码在你大脑里跑过了另一种。而中英文混杂,是因为不同语言在大脑中的翻译速度不同,譬如”So Tm True!”就是要表达“真他妈的对!” ,但“so”跑过了“真”,“Tm”跑过了”他妈的”,“True”跑过了“对”,最后讲出来就成了这样。

在英语地区待得久的人,讲英文成为了习惯,一下子反应过来就是它了。譬如在迟到的时候讲一句“sorry啊”,点餐的时候“请给我一个combo(套餐)”,分别的时候礼貌地say“那,See you later啦”等等,可能真不是要拿小学英语臭显摆,而是中英文在大脑里赛跑,某些英语单词跑得比中文快,所以就脱口而出了。
这种速度并不是你能完全控制的,更像是潜意识的行为,有时你甚至意识不到自己讲了英文。换个角度,其实老外在中国待久了也会语码转换失败,回国后也会英文夹中文。
台湾有一档综艺节目《请问你是哪里人》,节目组采访了来自意大利、德国、美国、法国等地的嘉宾,他们都在中国待了很久,中文讲得非常棒,棒到已经不会好好讲母语了,很多事情就回不去了。
譬如来自美国的杜力,回国后妈妈问他想要吃点什么:
——Do you want somecake,or some pie?
杜力想了一下,回答道:
——嗯…cake 吧!

老外在国内待久了,尚且会形成台湾腔的散装英语,Anyway,我们也就没必要苛责留学生的散装中文了吧?
没有的词儿让我怎么造?
除了习惯之外,有时候中文夹杂英文,是因为压根儿就没有另一种翻译,或者翻译的中文反而更加生僻,所以为了效率,我们会直接讲英文。
有些东西,如“Google”“FaceBook”“WTO”“KPI”等,我们第一次接触的就是英文,日常使用的也是英文表达,在讲话时,一定是英文语码跑得比中文快得多,所以自然而然就夹在中文里说了。如果还要专门在脑内翻译成中文再讲出来,实在是太麻烦了,而且沟通效率也很低。
想象你在工作的时候,同事突然滑到你旁边,告诉你:
——我的微软办公电子表格处理软件突然崩了,你能帮我看一下吗?

每个人都要反应好几秒,才能莫名其妙地回过神来,Excel就Excel,干嘛突然讲中文?所以在这种情况下,大家一般默认用英文,去他的中文翻译,如果有人连英文都听不懂,那么中文他更加听不懂。
更极端的情况是,有些单词在中文里没有,没有就是没有,所以英文是唯一准确的翻译。譬如你回国后跟朋友聊天,house可以说是别墅,townhouse是联排别墅,apartment是公寓,那么unit怎么说?
在国外,Unit一般是指三层到五层的小户型公寓,楼层不高但很长,一层楼有3、4户人家,没有电梯、洗衣房等设施,所有住户一起分享楼下的院子。Unit有点像国内的安置房,但又不完全是一回事,所以当你想讲这个东西时,不是大脑里哪种翻译更快的问题,是你只剩下英语这一种翻译模式,自然会脱口而出“unit”这个单词。

unit长这样
这种翻译的困境在于,中文和英文并不是一一对应的,有些单词很相似,有些词却存在差异性,怎么翻译都无法弥补,如果硬要把英文说成中文,只能造成意义的缺失。
翻译家和语言学家Nida曾提出了“文化词语”这个概念,认为语言是文化的一部分,任何文本的意义都直接或者间接地反映源语言的文化,所以词语的最终意义也只能在相应的文化中去寻找答案。
Language is part of the culture, themeaning of any text, directly or indirectly, anti -Picture a correspondingculture, words meaning ultimately only to find its corresponding culture.
由于文化的不同,不同语言系统里的词语也是不尽相通的,有些词看起来相似,但词语背后承载的民族信息却不相同;有些词在其他文化框架里不存在,只能用源语言表达。说到底,你不能凭空造个词出来。
譬如留学生们很常用的presentation、assignment、essay、paper等词,由于国内外的教育方式不同,英文单词能够微妙且清晰地分辨出是哪一种作业;如果硬要翻译成中文,“小组展示”“课堂作业”“文章”“论文”等,则会失去很多框架意义。
除了英文,其他语言系统里也有一些中文无法表达的词语。
譬如丹麦语的“Smørhul”,是英文“butter hole”的意思,喝粥的时候扒开一个小洞,加一些黄油进去。这个词还有一些引申意义,是指两个好朋友窝在床上,会有小朋友或者猫猫狗狗特别爱凑过来,填满床的一个间隙,这个间隙也叫“Smørhul”。非常微妙和软萌的一个词,中文没有对应的单词,要表达这个感觉,可能得写一首诗。
德语也有一些比较中二的表达,譬如“Heimweh”是指思念家乡的痛苦,“Lebensmüde”指厌倦了生活本身而产生的疲惫感, “Torschlusspanik”是指由于年龄增长,对自己梦想无法完成的恐惧。
总而言之,语言和语言之间并不相通,如果非要把所有英文单词翻译成中文,那我只能感到“Weltschmerz”(指因为世界的不完美而感觉到的心痛)。

大家心里都有b数
有些英文单词明明可以翻译成中文,但大家仍然坚持夹在中文里讲,譬如最饱受诟病的“外企话术”:
——目前这个Campaign是Andrew own的,我和Fiona support,所以他不confrim的话CPS没法排,那样我是不会on brief的。
稍微正常一点的版本:
——这个项目的原则是“ASAP”,我觉得我们的报价是能Cover住的。
曾有人质疑,两个中国人之间为何要讲英文?其实,这些英语在某种程度上并不是英语本身,而更像一个体系的黑话,说这些话并不是为了装逼,而是为了更好和体系内的人沟通,在体系内说体系内的话,拉近距离,显得亲近,对体系外的人说体系内的话,则显得装逼。
当你置身于一种规约化语境中时,交谈双方都拥有一种“标识性尺度”,意味着大家都明白,这个场合该讲什么话,用哪种语码,大家心里都有一套标准话术,而有些话术就是英文单词。
譬如录综艺节目不会讲“提到”,而是用“cue”;粉丝之间会说“zqsg”“xswl”“nsdd”等;Rap圈的术语更多,譬如“freestyle”“Punchilne”“flow”“beats”等等,哦对了,还有“skr skr”。这些外人乍一听不伦不类的单词,其实是群体内部的术语,是为了方便内部人士沟通的。

一群后期之间的对话
类似的例子还有,留学生之间的常用句式:
——抱歉今天没办法陪大家去downtown逛街,我有assigment要找tutor复习。等midterm过了我们再约时间吧。我GPA最近很操蛋,而且requirement还差六个credit,不恶补不行。
程序员之间的术语更多,基本全是英文:bug/debug 、feedback、FPGA、FIFO等等。他们日常交流切磋代码心得时,基本都是中文里面夹英文单词,如果非要他们全部换成中文,真的没必要,因为工具书上也是这么写的,内部沟通很顺畅。
聊得多欢啊
正如上文所言,语言的目的就是让对方明白你的意思,所以很多中英夹杂的主要原因,就是为了提高交流的效率与沟通的速度。当然,要讲术语之前,首先得确认对方是圈内的人,毕竟你效率再高,对方也要能解码才行。
Anyway,如何分辨对方是装逼还是正常讲话呢?
——明天我朋友有个Assignment要Due。
这是讲话。
——Tomorrow我的Friend要交个作业。
这是装X。

参考文献:
#吴京的微博有多好笑#来自偶像包袱走失中心 – 微博 https://weibo.com/6967304132/IaphF1nw1?type=comment#_rnd1570689089098
为什么有些人喜欢中文夹英文单词?这是出于什么心态?- 知乎 https://www.zhihu.com/question/279293448
生活在高语境国家,拥有低语境思维该怎么办?- 知乎 https://www.zhihu.com/question/31103695
为什么大家不喜欢中文夹英文的说话方式?- 知乎 https://www.zhihu.com/question/22208250
关臣. 框架语义下中英文化词语的翻译策略[J]. 英语广场, 2019(8).
王荣富, 唐祖莲, WANGRong-fu, et al. 英语文化在翻译中的失落和不达[J]. 湖南工程学院学报(社会科学版), 2005(3).
▼
丝袜诱惑真的那么吸引人吗?
