乾明 边策 十三 郭一璞 发自 凹非寺 量子位 报道 | 公众号 QbitAI
又一年,Jeff Dean代表Google AI,总结过去一年AI大趋势。
这是姐夫作为Google AI大总管的例行年度汇报,也是全球AI——乃至前沿技术第一大厂的肌肉展示。
他说,过去的2019年,是非常激动人心的一年。
依旧是学术和应用两开花,开源和新技术同步推进。
从基础研究开始,到技术在新兴领域的应用,再到展望2020。
虽然汇报格式没有变化,但人工智能技术,又往前迈出了一大步。

Jeff Dean总结了16个大方面的AI成果,并透露全年AI论文发表数达754篇,平均每天都有2篇论文发表。
涵盖AutoML、机器学习算法、量子计算、感知技术、机器人、医疗AI、AI向善……
桩桩件件,不仅在当前推动了AI作用社会方方面面,而且也是对未来趋势的小小展示。
毫不夸张地说,欲知2019 AI技术进展,看Jeff这篇总结再合适不过;欲知2020 AI会走向何方,看Jeff这篇也能获益良多。

为了方便阅读,我们先整理了一个小目录给你:
机器学习算法:理解神经网络中动态训练性质
AutoML:持续关注,实现机器学习自动化
自然语言理解:结合多种方式、任务,提高技术水平
机器感知:对图像、视频、环境更深入理解和感知
机器人技术:自监督方式训练,发布机器人测试基准
量子计算:首次实现量子优越性
AI在其他学科的应用:从苍蝇的脑子到数学,还有化学分子研究和艺术创作
手机AI应用:本地部署的语音、图像识别模型,还有更强的翻译、导航和拍照
健康和医疗:已用于乳腺癌、皮肤病的临床诊断
AI辅助残障人士:用图像识别、语音转写技术造福弱势群体
AI促进社会公益:预告洪水、保护动植物、教小朋友识字学数学,还砸了1个多亿做了20个公益项目
开发者工具打造和造福研究者社区:TensorFlow迎来全面升级
开放11个数据集:从强化学习到自然语言处理,再到图像分割
顶会研究和Google研究的全球扩张:发表大量论文,投入大量资源资助教师、学生和各方面研究人员进行研究
人工智能伦理:推进人工智能在公平、隐私保护、可解释性方面研究进展
展望2020年及以后:深度学习革命将继续重塑我们对计算和计算机的看法。
2019年,Google在机器学习算法和方法的许多不同领域进行了研究。
一个主要的焦点是理解神经网络中动态训练的性质。
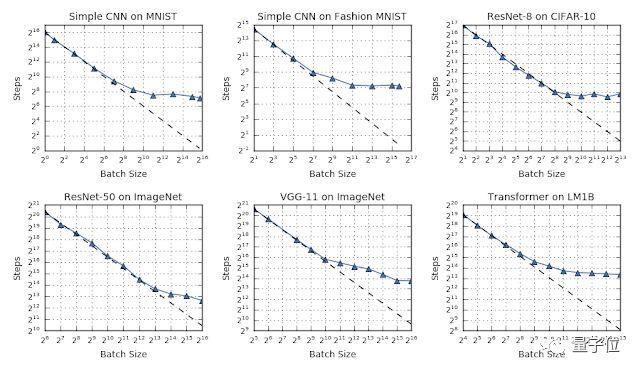
在下面这项研究中,研究人员的实验结果表明,缩放数据并行量可以让模型收敛更快有效。
论文地址:
https://arxiv.org/pdf/1811.03600.pdf
与数据并行性相比,模型并行性可以是扩展模型的有效方法。
GPipe是一个可以让模型并行化更加有效的库:
当整个模型的一部分在处理某些数据时,其他部分可以做别的工作,计算不同的数据。
这种pipline方法可以组合在一起,来模拟更有效的batch大小。
GPipe库地址:
https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html
当机器学习模型能够获取原始输入数据,并学习“disentangled”高级表示形式时,它们是非常有效的。
这些表示形式通过用户希望模型能够区分的属性来区分不同种类的示例。
机器学习算法的进步,主要是为了鼓励学习更好的表示法,以此来推广到新的示例、问题及领域。
2019年,Google在不同的背景下研究了这方面的问题:
比如,他们检查了哪些属性影响了从无监督数据中学习的表示,以便更好地理解什么因素能够有助于良好的表示和有效的学习。
博客地址:https://ai.googleblog.com/2019/04/evaluating-unsupervised-learning-of.html
Google表明可以使用margin分布的统计量来预测泛化差距,有助于了解哪种模型最有效地进行了泛化。
除此之外,还在强化学习的背景下研究了Off-Policy分类,以便更好地理解哪些模型可能泛化得最好。

博客地址:https://ai.googleblog.com/2019/07/predicting-generalization-gap-in-deep.html
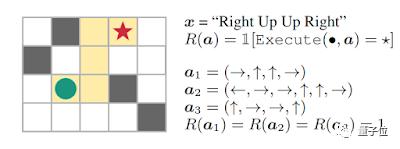
研究了为强化学习指定奖励功能的方法,使学习系统可以更直接地从真实目标中进行学习。
博客地址:
https://ai.googleblog.com/2019/02/learning-to-generalize-from-sparse-and.html
Google在2019年依然持续关注着AutoML。
这种方法可以实现机器学习许多方面的自动化,并且在某些类型的机器学习元决策方面,通常可以取得更好的结果,比如:
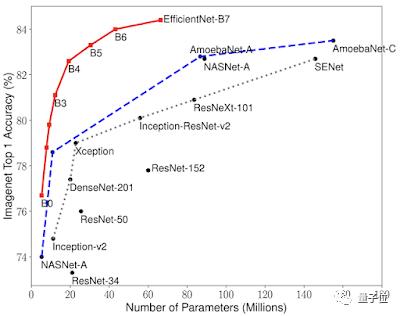
Google展示了如何使用神经结构搜索技术,在计算机视觉问题上获得更好的结果,其在ImageNet上的正确率为84.4%,而参数比以前的最佳模型少8倍。
博客地址:https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html
Google展示了一种神经架构搜索方法,展示了如何找到适合特定硬件加速器的高效模型。从而为移动设备提供高精度、低计算量的运行模型。
博客地址:https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
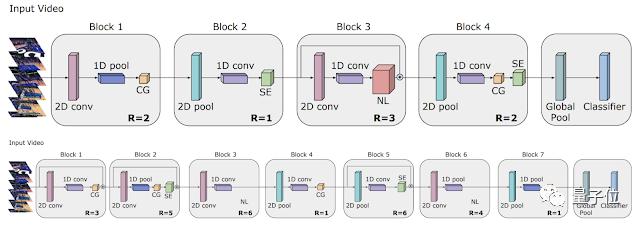
Google展示了如何将AutoML工作扩展到视频模型领域,如何找到能够实现最先进结果的架构,以及能够匹配手工模型性能的轻量级架构。
结果使计算量减少了50倍。
博客地址:https://ai.googleblog.com/2019/10/video-architecture-search.html
Google开发了用于表格数据的AutoML技术,并合作发布了这项技术,作为Google Cloud AutoML Tables的新产品。
博客地址:https://ai.googleblog.com/2019/05/an-end-to-end-automl-solution-for.html
展示了如何在不使用任何训练步骤,来更新被评估模型的权重的情况下,找到有趣的神经网络架构,让结构搜索的计算效率更高。
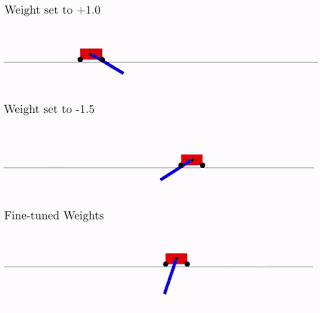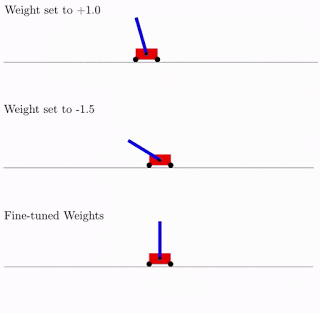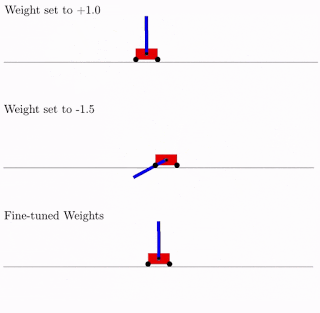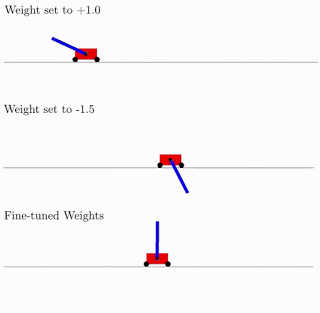
博客地址:https://ai.googleblog.com/2019/08/exploring-weight-agnostic-neural.html
探索了发现NLP任务的体系结构。这些任务的性能明显优于普通的Transformer模型,并且大大降低了计算成本。
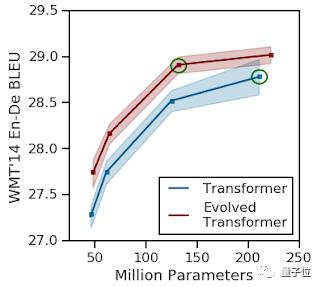
博客地址:
https://ai.googleblog.com/2019/06/applying-automl-to-transformer.html
研究证明了自动学习数据增强方法可以扩展到语音识别模型中。
与现有的人类ML-expert驱动的数据增强方法相比,可以在较少数据情况下获得了显著更高的准确性。
博客地址:https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html
推出了第一款使用AutoML进行关键字识别和口语识别的语音应用程序。
在实验中,发现了比人类设计更好的模型:效率更高,性能也更好。
博客地址:https://www.isca-speech.org/archive/Interspeech_2019/abstracts/1916.html
在过去几年里,自然语言理解、翻译、自然对话、语音识别和相关任务的模型取得了显著进展。
Google在2019年工作的一个主题是:
通过结合各种方式或任务来提高技术水平,以此来训练更强大的模型。
比如,只用1个模型,在100种语言之间进行翻译训练(而不是使用100个不同的模型),从而显著提高了翻译质量。


博客地址:https://ai.googleblog.com/2019/10/exploring-massively-multilingual.html
展示了如何将语音识别和语言模型结合起来,并在多种语言上训练系统,可以显著提高语音识别的准确性。
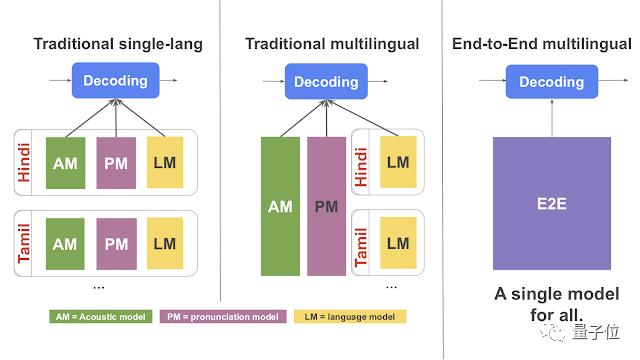
博客地址:https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
研究证明,训练一个联合模型来完成语音识别、翻译和文本到语音的生成任务是有可能的。
并且还具有一定的优势,例如在生成的翻译音频中保留说话人的声音, 以及更简单的整体学习系统。
博客地址:https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html
研究展示了如何结合许多不同的目标,来生成在语义检索方面明显更好的模型。
例如,在GoogleTalk to Books中提问,“什么香味能唤起回忆?”
结果是,“对我来说,茉莉花的香味和烤盘的香味,让我想起了我无忧无虑的童年。”
博客地址:https://ai.googleblog.com/2019/07/multilingual-universal-sentence-encoder.html
展示了如何使用对抗性训练程序来显著提高语言翻译的质量和鲁棒性。
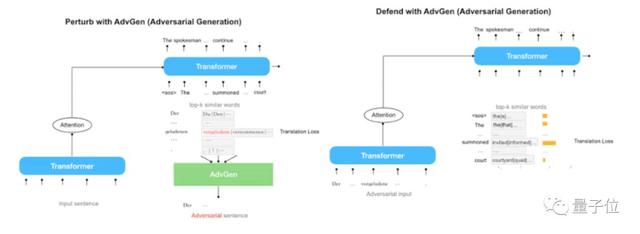
博客地址:https://ai.googleblog.com/2019/07/robust-neural-machine-translation.html
随着基于seq2seq、Transformer、BERT、Transformer-XL和ALBERT等模型的发展,Google的语言理解技术能力不断提高。并已经应用到了许多核心产品和功能中。
2019年,BERT在核心搜索和排名算法中的应用,带来了过去五年里搜索质量的最大提升(也是有史以来最大的提升之一)。
在过去十年中,用于更好地了解静态图像的模型取得了显著进步。
接下来是Google在过去一年中,在这个领域中的主要研究。
包括图像和视频的更深入的理解,以及对生活和环境的感知,具体有:
研究了镜头中更细粒度的视觉理解,支持更强大的视觉搜索。
博客地址:https://www.blog.google/products/search/helpful-new-visual-features-search-lens-io/
展示了Nest Hub Max的智能相机功能,例如快速手势、面部匹配和智能视频通话取景。
博客地址:https://blog.google/products/google-nest/hub-max-io/
研究了更好的视频深度预测模型。
博客地址:https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
研究使用时间周期一致性,学习对视频进行细粒度时间理解的更好表示。

博客地址:https://ai.googleblog.com/2019/08/video-understanding-using-temporal.html
学习文本、语音和视频中与未标记视频在时间上一致的表示形式。
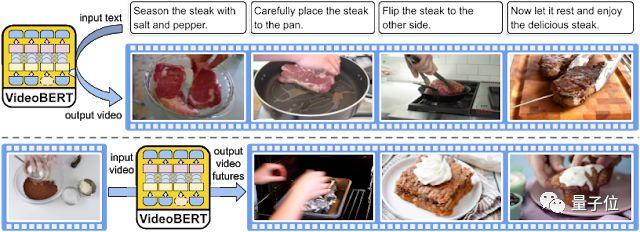
博客地址:https://ai.googleblog.com/2019/09/learning-cross-modal-temporal.html
也能够通过对过去的观察,来预测未来的视觉输入。
博客地址:https://ai.googleblog.com/2019/03/simulated-policy-learning-in-video.html
并证明了模型可以更好地理解视频中的动作序列。

博客地址:https://ai.googleblog.com/2019/04/capturing-special-video-moments-with.html
机器学习在机器人控制中的应用是Google的重要研究领域。Google认为,这是使机器人能够在复杂的现实世界环境(比如日常家庭、企业)中有效运行的重要工具。
Google2019年在机器人技术中所做的工作包括:
1、在通过自动强化学习进行远程机器人导航中,Google展示了如何将强化学习与远程项目结合,使机器人能够更有效地在复杂的环境(例如Google办公大楼)中导航。
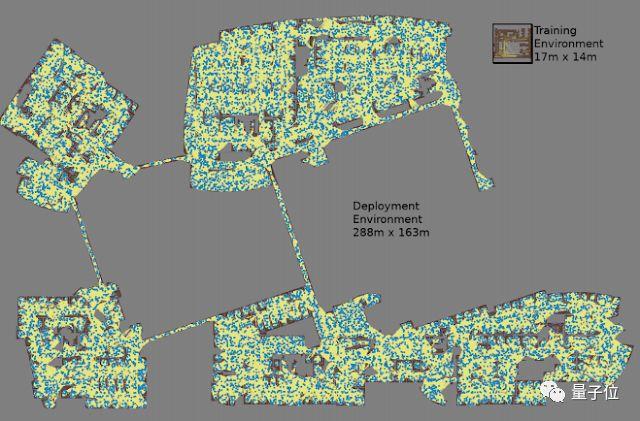
相关链接:
https://ai.googleblog.com/2019/02/long-range-robotic-navigation-via.html
2、在PlaNet中,Google展示了只从图像中有效地学习世界模型,以及如何利用这种模型以更少的学习次数完成任务。
相关链接:https://ai.googleblog.com/2019/02/introducing-planet-deep-planning.html
3、在TossingBot上,Google将物理定律和深度学习统一起来,让机器人通过实验来学习直观物理原理,然后将物体按照学习到的规律扔进盒子里。

相关链接:
https://ai.googleblog.com/2019/03/unifying-physics-and-deep-learning-with.html
4、在Soft Actor-Critic的研究中中,Google证明了,训练强化学习算法的方式,既可以通过最大化期望的奖励,也可以通过最大化策略的熵来实现。
这可以帮助机器人学习得更快,并且对环境的变化更加鲁棒。
相关链接:https://ai.googleblog.com/2019/01/soft-actor-critic-deep-reinforcement.html
5、Google还发展了机器人的自监督学习算法,让机器人以自监督的方式,通过分解物体的方式物来学习组装物体。这表明机器人可以和儿童一样,从拆解中学到知识。

相关链接:https://ai.googleblog.com/2019/10/learning-to-assemble-and-to-generalize.html
6、最后,Google还推出了低成本机器人的基准测试ROBEL,这是一个针对低成本机器人的开源平台,帮助其他开发者更快更方便地研发机器人硬件。
相关链接:https://ai.googleblog.com/2019/10/robel-robotics-benchmarks-for-learning.html
在2019年,Google在量子计算上取得了重大图片,首次向世人展示了量力优越性:在一项计算任务中,量子计算机的速度远远超过经典计算机。
原本经典计算机需要计算10000年的任务,量子计算机仅需200秒即可完成。这项研究登上了今年10月24日Nature杂志的封面。

GoogleCEO皮查伊说:“它的意义就像第一枚火箭成功地脱离地球引力,飞向太空边缘。”量子计算机会在材料科学、量子化学和大规模优化等领域中发挥重要的作用。
Google还在努力使量子算法更易于表达、更易于控制硬件,并且Google已经找到了在量子计算中使用经典机器学习技术的方法。
人工智能和机器学习在其他科学领域的应用方面,Google发了很多论文,主要是在多组织协作方面。
论文集:https://research.google/pubs/?area=general-science
今年的重点有:
苍蝇大脑交互性自动3D重建,用机器学习模型来精心绘制苍蝇大脑的每个神经元,Jeff Dean称这是映射苍蝇大脑结构的的里程碑。

相关博客:https://ai.googleblog.com/2019/08/an-interactive-automated-3d.html
在为偏微分方程学习更好的仿真方法中,Google用机器学习加速偏微分方程计算,这也是研究气候变化、流体动力学、电磁学、热传导和广义相对论等基础计算问题的核心。
Google还用机器学习模型判断气味,用GNN判断分子结构,来预测它闻起来是什么味儿。
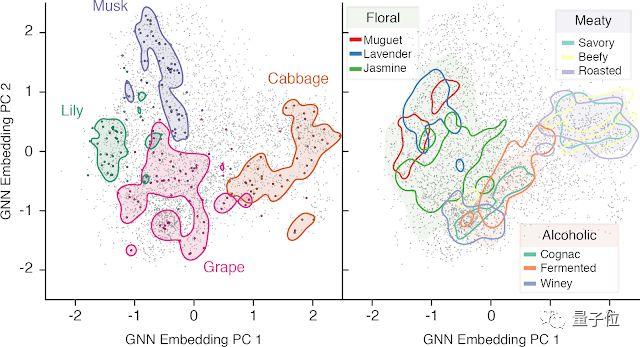
相关报道:Google造出AI调香师:看一眼分子结构,就知道它闻起来什么味儿
同样在化学方面,Google还做了一个强化学习框架来优化分子。
相关论文:https://www.nature.com/articles/s41598-019-47148-x
艺术创作方面,GoogleAI的努力就更多了,比如AI+AR的艺术表现

https://www.blog.google/outreach-initiatives/arts-culture/how-artists-use-ai-and-ar-collaborations-google-arts-culture/
用机器重新编排舞蹈:
https://www.blog.google/technology/ai/bill-t-jones-dance-art/
AI作曲的新探索:
https://www.blog.google/technology/ai/behind-magenta-tech-rocked-io/
还延伸出了一个好玩的AI作曲Doodle:
https://www.blog.google/technology/ai/honoring-js-bach-our-first-ai-powered-doodle/
Google做的很多事情都是借机器学习赋予手机新的能力,这些模型都能在手机端运行,就算开了飞行模式,这些功能依然可以使用。
现在,手机端语音识别模型、视觉模型、手写识别模型都已经实现了。
相关博客:
语音识别https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html视觉模型https://ai.googleblog.com/2019/11/introducing-next-generation-on-device.html手写识别模型https://ai.googleblog.com/2019/03/rnn-based-handwriting-recognition-in.html
Jeff Dean称,这为实现更强大的新功能铺平了道路。
此外,今年Google在手机上的亮点有:
Live Caption功能,手机上任何应用播放的视频,它都能给自动加上字幕。

相关博客:https://ai.googleblog.com/2019/10/on-device-captioning-with-live-caption.html
Recorder应用,让你能搜索手机录下的音频中的内容。
相关博客:https://ai.googleblog.com/2019/12/the-on-device-machine-learning-behind.html
Google翻译的拍照翻译功能也做了升级,新增支持阿拉伯语、印地语、马来语、泰语和越南语等多种语言的支持,而且不只是英语和其他语言翻译,英语之外的其他语言互译也可以了,还能自动找到相机画幅中的文字在哪里。

相关博客:https://www.blog.google/products/translate/google-translates-instant-camera-translation-gets-upgrade/
还在ARCore里发布了一个面部增强API,帮你实现实时的AR玩法。

面部增强API:https://developers.google.com/ar/develop/java/augmented-faces/
还有移动端手势识别,这个做好之后就能做手势交互了。

相关报道:Google开源手势识别器,手机能用,运行流畅,还有现成的App,但是被我们玩坏了
还用RNN改进了手机屏幕上的手写输入识别。

相关博客:https://ai.googleblog.com/2019/03/rnn-based-handwriting-recognition-in.html
在导航定位方面,GPS往往只是大致定位,但AI可以发挥关键作用。

结合Google街景的数据,举着手机转一圈,手机就会变成一个认路的朋友一样,照着街景和地图给你指出来:这是哪栋楼,这是哪条街,这是南这是北,你该朝这儿走。

相关博客:https://ai.googleblog.com/2019/02/using-global-localization-to-improve.html
另外,为了保证用户隐私,Google也一直在研究联合学习,下面这篇论文就是2019年Google团队转写的关于联合学习进展的文章:
https://arxiv.org/abs/1912.04977
还有老生常谈的手机拍照,Google2019年提升了手机自拍的能力。

相关博客:https://ai.googleblog.com/2019/04/take-your-best-selfie-automatically.html
背景虚化和人像模式也在2019年获得了提升。

相关博客:https://ai.googleblog.com/2019/12/improvements-to-portrait-mode-on-google.html
夜景挑战拍星星也有巨大的提升,还发了SIGGRAPH Asia的论文。

相关博客:https://ai.googleblog.com/2019/11/astrophotography-with-night-sight-on.html
相关论文:https://arxiv.org/abs/1905.03277https://arxiv.org/abs/1910.11336
2019年是Google Health团队经历的第一个完整年。
在2018年末,Google将Google Research健康团队、Deepmind Health和与健康相关的硬件部门重组,新建了Google Health团队。
1、在疾病的诊断和及早发现上,Google做出了多项成果:
用深度学习模型发现乳腺癌,准确性高于人类专家,降低了诊断中的假阳性和假阴性案例。这项研究不久前刚登上Nature杂志。
相关链接:
谷歌AI乳腺癌检测超过人类,LeCun质疑引起讨论,但平胸妹子可能不适用

另外,Google还在皮肤疾病诊断、预测急性肾损伤、发现早期肺癌方面均做出一些新成果。
2、Google将机器学习与其他技术结合用在其他医疗技术中,比如在显微镜中加入增强显示技术,帮助医生快速定位病灶。
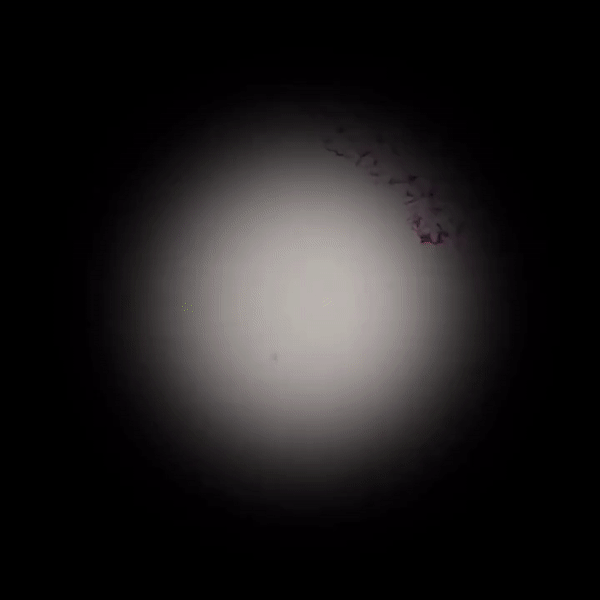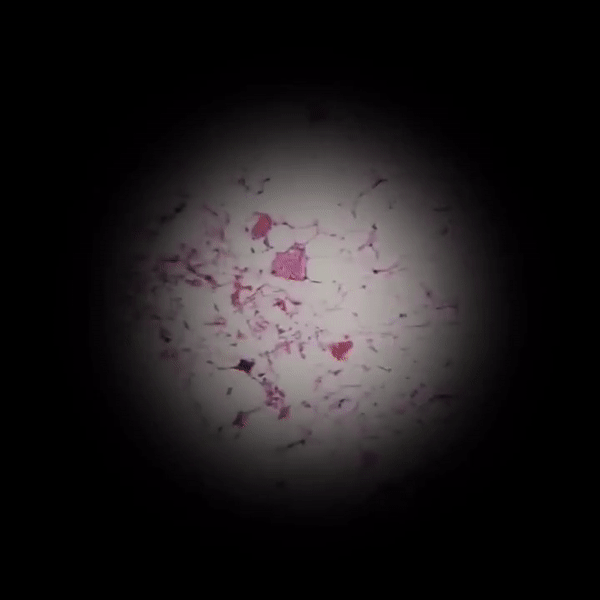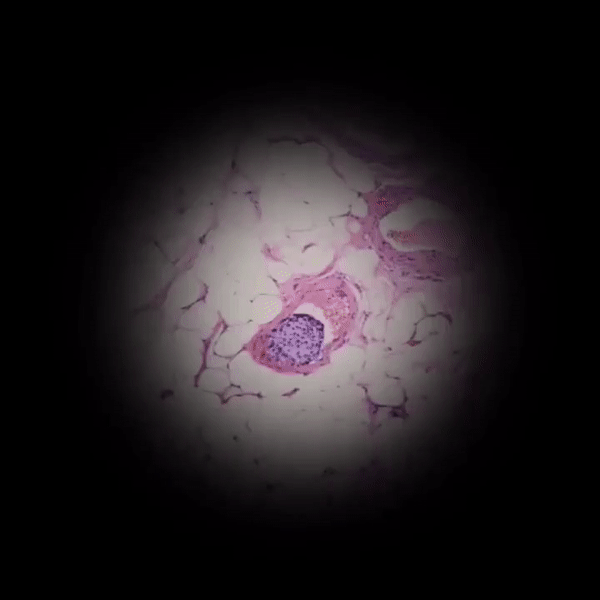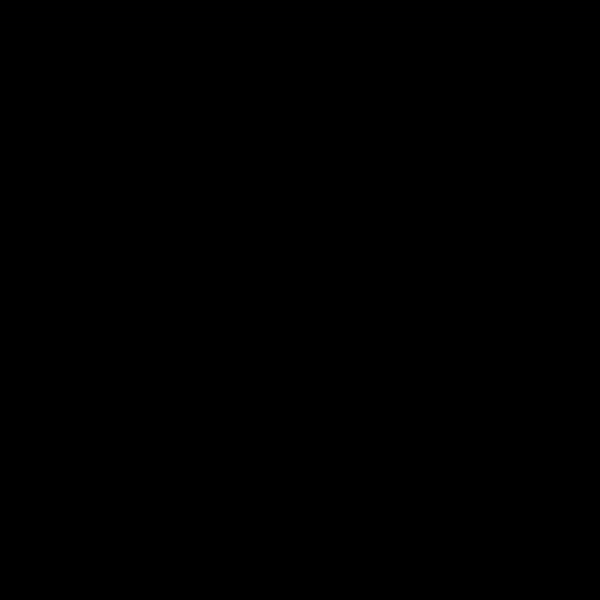
相关链接:
AI实时筛查癌细胞,普通显微镜简单改装就能用,谷歌新突破登上Nature子刊
Google还为病理学家构建了以人为中心的相似图像搜索工具,允许检查相似病例来帮助医生做出更有效的诊断。
AI与我们的生活越来越紧密。在过去的一年里,Google用AI为我们的日常生活提供帮助。
我们可以很容易看到美丽的图像,听到喜欢的歌曲,或与亲人交谈、然而,全球有超过十亿人无法用这些方式了解世界。
机器学习技术可以通过将这些视听信号转换成其他信号,为残障人士服务。Google提供的AI助手技术有:
Lookout帮助盲人或视力低下的人识别其周围环境信息。
实时转录技术Live Transcribe帮助聋哑或听障碍人士将语音快速转化为文字。
相关链接:
谷歌AI拜大年:为聋哑人带来科技福利,首页涂鸦有惊喜
Euphonia项目实现了个性化的语音到文本转换。对于患有渐冻症等疾病导致口齿不清的人,这项研究,提高了自动语音识别的准确率。
另外还有一个Parrotron项目,也是使用端到端神经网络来帮助改善交流,但是研究重点是语音到语音的转换。
对于盲人和弱视人群,Google利用AI技术来产生图像的描述。当屏幕阅读器遇到无描述的图像或图形时,Chrome现在可以自动创建描述内容。
音频形式读取文本的工具Lens for Google Go,极大地帮助了那些文盲用户在单词的世界中获取信息。

Jeff Dean说,机器学习对解决许多重大社会问题有巨大的意义,Google一直在一些社会问题领域做出努力,致力于让其他人能用创造力和技能来解决这些问题。
比如洪水问题,每年都有数亿人遭受洪水影响。Google用机器学习、计算和更好的数据库,来做出洪水预测,并给受影响地区的数百万人发送警报。
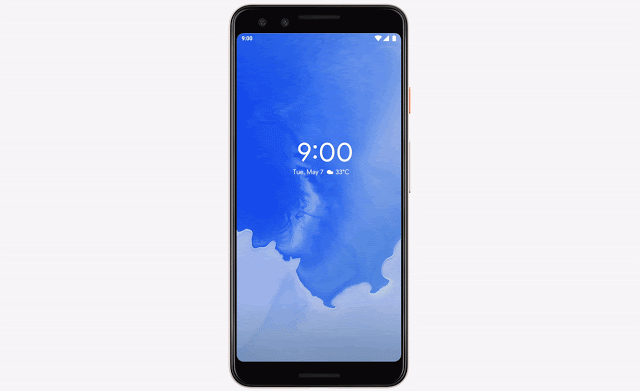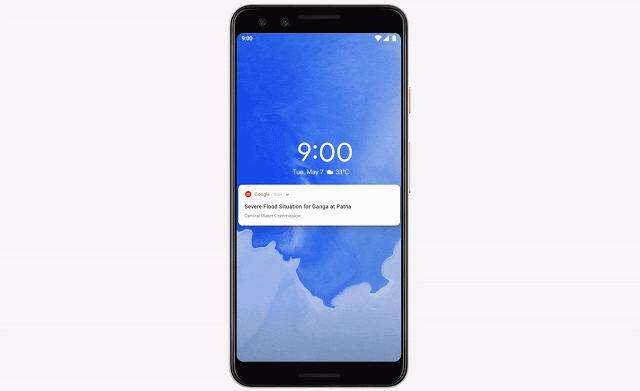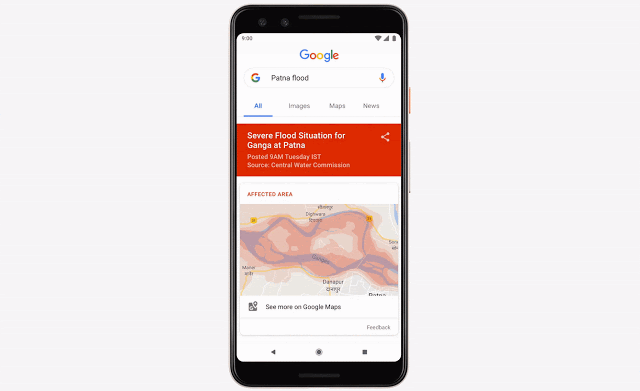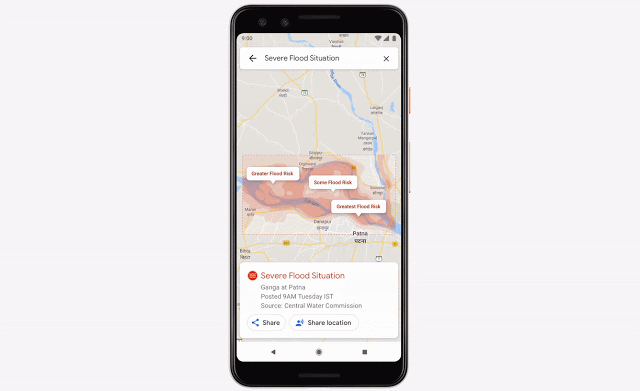
甚至,他们还办了一个workshop,找了许多研究人员来专门解决这个问题。
相关博客:https://www.blog.google/technology/ai/tracking-our-progress-on-flood-forecasting/https://ai.googleblog.com/2019/09/an-inside-look-at-flood-forecasting.htmlhttps://ai.googleblog.com/2019/03/a-summary-of-google-flood-forecasting.html
另外,Google还做了一些机器学习和动植物研究相关的工作。
他们与七个野生动物保护组织合作,用机器学习帮助分析野生动物的照片数据,找到这些野生动物的群落都在哪里。
相关博客:https://www.blog.google/products/earth/ai-finds-where-the-wild-things-are/
Google还和美国海洋和大气管理局合作,借助水下的声音数据判断鲸的种群位置。
相关博客:https://www.blog.google/technology/ai/pattern-radio-whale-songs/
Google发布了一套工具,用机器学习研究生物多样性。
相关博客:A New Workflow for Collaborative Machine Learning Research in Biodiversityhttps://ai.googleblog.com/2019/10/a-new-workflow-for-collaborative.html
他们还举办了一个Kaggle比赛,用计算机视觉给木薯叶子上的各种疾病分类。木薯是非洲第二大碳水化合物来源,木薯的病害影响人们的视频安全问题。
https://www.kaggle.com/c/cassava-disease
Google Earth的Timelapse功能也得到了更新,甚至你还可以从这里看到人口流动和迁移的数据。

相关博客:https://ai.googleblog.com/2019/06/an-inside-look-at-google-earth-timelapse.htmlhttps://ai.googleblog.com/2019/11/new-insights-into-human-mobility-with.html
对于教育方面,Google做了带语音识别技术的Bolo应用,指导小朋友们学英语。这个应用部署在了本地,可以离线运行,它已经帮助80万印度儿童识字,小朋友们累计读了了10亿单词,在印度200个村子的试点中,64%的小朋友阅读能力有所提高。
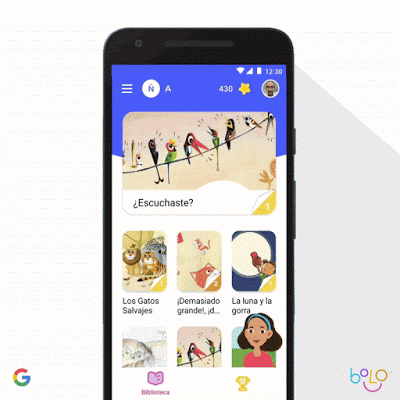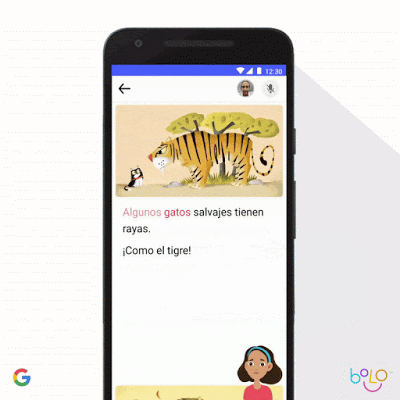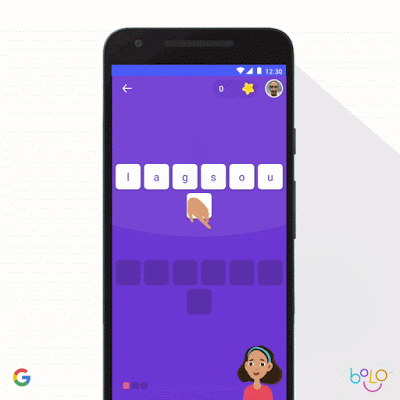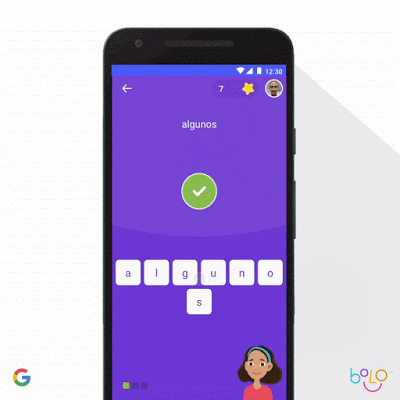
仿佛是一个Google版的英语流利说。
相关博客:https://www.blog.google/technology/ai/bolo-literacy/
除了识字,还有数学、物理等更复杂的学习科目。Google做了Socratic应用来帮高中生学数学。
此外,为了让AI在公益方面发挥更大的作用,Google举办了AI Impact Challenge,收集到了来自119个国家超过2600个提案。
最终20个能解决重大社会问题和环境问题的提案脱颖而出,Google在这些提案项目上投入了2500万美元(超过1.7亿人民币)的资助,做出了一些成绩,包括:
无国界医生组织(MSF)创建了一个免费手机App,用图像识别工具帮助条件不好的地方的诊所医生分析抗菌图像,为给病人用什么药提供建议,这个项目已经在约旦试点。
无国界医生组织的项目报道:https://www.doctorswithoutborders.org/what-we-do/news-stories/news/msf-receives-google-grant-develop-new-free-smartphone-app-help
世界上有十亿人靠小型农场过活,但一旦发生病虫害,就会断了他们的活路。
因此,一家名叫Wadhwani AI的NPO,用图像分类模型来辨别农场中的害虫,并对于应该喷哪种农药、何时喷药给出建议,提高了农作物的产量。
热带雨林的非法砍伐是气候变化的主要影响因素,一个名叫“雨林连接(Rainforest Connection)”的组织用深度学习进行生物声学检测,拿一些旧手机就可以跟踪雨林的健康状况,检测其中的威胁。

作为全球第一AI大厂,Google也是开源先锋,不断为社区发光发热,一方面是集中在TensorFlow上。
Jeff Dean说,因为TensorFlow 2.0发布,对于开源社区来说,过去一年是激动人心的一年。
这是TensorFlow发布以来,第一次重大升级,使构建ML系统和应用程序比以往任何时候都要容易。
量子位相关报道如下:
GoogleTF2.0凌晨发布!“改变一切,力压PyTorch”

在TensorFlow Lite中,他们增加了对快速移动GPU推理的支持;并发布了Teachable Machine 2.0,不需要写代码,只需一个按钮就能训练一个机器学习模型。
量子位相关报道如下:
TensorFlow Lite发布重大更新!支持移动GPU、推断速度提升4-6倍
还有MLIR,一个开源的机器学习编译器基础工具,解决了日益增长的软件和硬件碎片的复杂性,使构建人工智能应用程序的更容易。
在NeurIPS 2019上,他们展示了如何使用开源的高性能机器学习研究系统JAX:
https://nips.cc/Conferences/2019
此外,他们也开源了用于构建感知和多模态应用ML pipelines的框架MediaPipe:
https://github.com/google/mediapipe

以及高效浮点神经网络推理操作符库XNNPACK:
https://github.com/google/XNNPACK
当然,Google还放出了一些羊毛给大家薅。
Jeff Dean介绍称,截止2019年底,他们让全球超过1500名研究人员通过 TensorFlow Research Cloud 免费访问了Cloud TPU,他们在 Coursera 上的入门课程已经有超过了10万名学生等等。
同时,他也介绍了一些“暖心”案例,比如在 TensorFlow 的帮助下,一名大学生发现了两颗新的行星,并建立了一种方法来帮助其他人发现更多的行星。
还有大学生们使用 TensorFlow 来识别洛杉矶的坑洞和危险的道路裂缝等等。
另一方面是在开放数据集上。
2018年发布了数据集搜索引擎后,Google今年依旧在这方面努力,并尽自己的努力,给这个搜索引擎添砖加瓦。

过去一年,Google在各个领域开放了11个数据集,下面开始资源大放送,请收好~
Open Images V5,在注释集中加入分割掩码(segmentation masks),样本规模达到280万,横跨350个类别,量子位报道:
280万样本!Google开放史上最大分割掩码数据集,开启新一轮挑战赛
“自然问题”数据集,第一个使用自然发生的查询,并通过阅读整个页面找到答案的数据集,而不是从一小段中提取答案,30万对问答,BERT都达不到70分,量子位报道:
Google发布超难问答数据集「自然问题」:30万对问答,BERT都达不到70分
用于检测deepfakes的数据集:
https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html
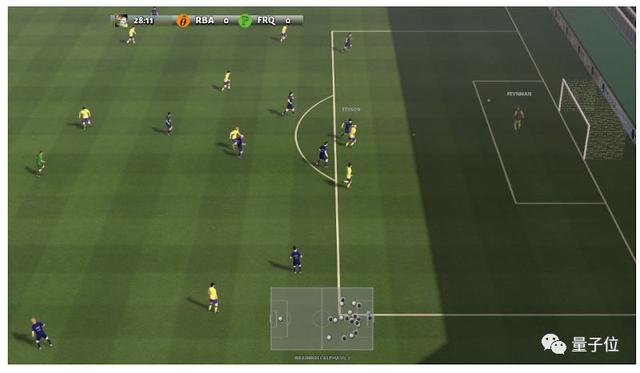
足球模拟环境Google Research Football,智能体可以在这个宛若FIFA的世界里自由踢球,学到更多踢球技巧,量子位报道:
Google造了个虚拟足球场,让AI像打FIFA一样做强化学习训练丨开源有API
地标数据集Google-Landmarks-v2:包括500万张图片,地标数量达到20万,量子位报道:
500万张图片,20万处地标风景,Google又放出大型数据集
YouTube-8M Segments数据集,一个大规模的分类和时间定位数据集,包括YouTube-8M视频5秒片段级别的人工验证标签:
https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
AVA Spoken Activity数据集,一个多模态音频+视觉视频的感知对话数据集:
https://research.google.com/ava/
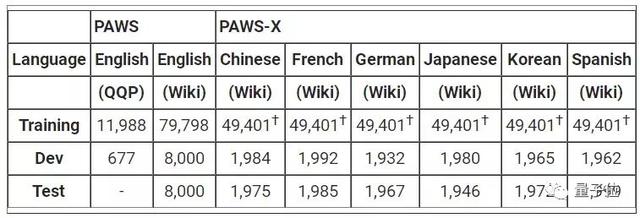
PAWS和PAWS-X:用于机器翻译,两个数据集都由高度结构化的句子对组成,并且相互之间的词汇重叠度很高,其中约占一半的句子具有对应的多语言释译:
https://ai.googleblog.com/2019/10/releasing-paws-and-paws-x-two-new.html
让两个人进行对话,通过数字助手模拟人类的对话的自然语言对话数据集:
https://ai.googleblog.com/2019/09/announcing-two-new-natural-language.html
Visual Task Adaptation Benchmark:这是对标 GLUE、ImageNet,Google推出的视觉任务适应性基准。
有助于用户更好地理解哪些哪些视觉表征可以泛化到更多其他的新任务上,从而减少所有视觉任务上的数据需求:
https://ai.googleblog.com/2019/11/the-visual-task-adaptation-benchmark.html
最大的面向任务的对话的公开数据库——模式引导对话数据集,有跨越17个域的超过18000个对话:
https://ai.googleblog.com/2019/10/introducing-schema-guided-dialogue.html
根据Google官方统计,Googler在过去一年发表了754篇论文。
Jeff Dean也列举了一些顶会战绩:
CVPR有40多篇论文,ICML有100多篇论文,ICLR有60多篇论文,ACL有40多篇论文,ICCV有40多篇论文,NeurIPS有超过120篇等等。

他们还在Google举办了15个独立的研讨会,主题从改善全球洪水预警,到如何使用机器学习来建立更好地为残疾人服务的系统,到加速开发用于量子处理器(NISQ)的算法、应用程序和工具等等。
并通过年度博士奖学金项目在全球资助了50多名博士生,也对创业公司提供了支持等等。
同样,2019年Google研究地点依旧在全球扩张,在班加罗尔开设了一个研究办公室。同时,Jeff Dean也发出了招聘需求:如果有兴趣,赶紧到碗里来~
和往年一样,这篇报道最开篇,其实Jeff首先谈到的就是Google在人工智能伦理上的工作。
这也是Google在AI实践和道德伦理、技术向善方面的明确宣示。
2018年,Google发布了AI 七原则并围绕这些原则展开应用实践。2019年6月,Google交出成绩单,展示了如何在研究和产品开发中,将这些原则付诸实施。
报告链接:https://www.blog.google/technology/ai/responsible-ai-principles/
Jeff Dean说,由于这些原则基本覆盖人工智能和机器学习研究中最活跃的领域,比如机器学习系统中的偏见、安全、公平、可靠性、透明度和隐私等等。

因此Google的目标是将这些领域的技术应用到工作中,并不断进行研究,以继续推进相关技术发展。
一方面,Google还在KDD’19、AIES 19等学术会议上发表了多篇论文,来探讨机器学习模型的公平性和可解释性。
比如,对Activation Atlases如何帮助探索神经网络行为,以及如何帮助机器学习模型的可解释性进行研究。
相关链接:Exploring Neural Networks with Activation Atlaseshttps://ai.googleblog.com/2019/03/exploring-neural-networks.html
另一方面,Google的努力也都落到了实处,切实的拿出了的产品。
比如,发布了TensorFlow Privacy,来帮助训练保证隐私的机器学习模型。
相关链接:Introducing TensorFlow Privacy: Learning with Differential Privacy for Training Datahttps://blog.tensorflow.org/2019/03/introducing-tensorflow-privacy-learning.html
此外,Google还发布了一个新的数据集,以帮助研究识别deepfakes。
相关链接:Contributing Data to Deepfake Detection Researchhttps://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html

最后,Jeff也站在过去10年的发展历程上,对2020年及以后的研究动向进行了展望。
他说,在过去的十年里,机器学习和计算机科学领域取得了显著的进步,我们现在让计算机比以往任何时候都更有能力去看、听和理解语言。
在我们的口袋里,有了复杂的计算设备,可以利用这些能力,更好地帮助我们完成日常生活中的许多任务。
我们围绕这些机器学习方法,通过开发专门的硬件,重新设计了我们的计算平台,使我们能够处理更大的问题。
这些这改变了我们对数据中心中的计算设备的看法,而深度学习革命,将继续重塑我们对计算和计算机的看法。

与此同时,他也指出,还有大量未解决的问题。这也是Google在2020年及以后的研究方向:
第一,如何构建能够处理数百万任务的机器学习系统,并能够自动成功地完成新任务?
第二,如何才能在人工智能研究的重要领域,如避免偏见、提高可解释性和可理解性、改善隐私和确保安全等方面,取得最先进的进展?
第三,如何应用计算和机器学习在重要的科学新领域取得进展?比如气候科学、医疗保健、生物信息学和许多其他领域等等。
第四,关于机器学习和计算机科学研究社区追求的思想和方向,如何确保有更多不同的研究人员提出和探索?我们如何才能最好地支持来自不同背景的新研究人员进入这一领域?
最后的最后,你怎么看Google AI在过去一年的突破与进展?
欢迎在留言区互动~
报告传送门:https://ai.googleblog.com/2020/01/google-research-looking-back-at-2019.html
Google 2019论文传送门:https://research.google/pubs/?year=2019
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态